Multi-Value Dimensions in Apache Druid (Part 5)
An interesting discussion that I had with a Druid user prompts me to continue the loose miniseries about multi-value dimensions in Apache Druid. The previous posts can be found here:
In part 1 I pointed out what multi-value dimensions (MVD) are, and how they behave with respect to GROUP BY (they do an implicit unnest or, if you will, a lateral join), and also with respect to filtering using a WHERE clause (you get all the rows that match the WHERE condition, but no unnesting happens.)
But what if you want to combine grouping and filtering? The behavior of Druid in these case could be a bit surprising. Let’s have a look!
I am using Imply’s version 2023.03.01 of Druid, because I am going to show a few things using Imply’s graphical frontend. If you want to run the SQL examples only, Druid 25 quickstart works fine.
We are using the ristorante datasource from part 3; to create the datasource, follow the instructions given there. (You can make your life a bit easier because by now, Druid allows specifying the multi-value handling mode in the wizard.)
Start with a simple analysis, breaking down the count of items by item and customer:
SELECT customer, orders, COUNT(*) AS numOrders
FROM "ristorante"
GROUP BY 1,2
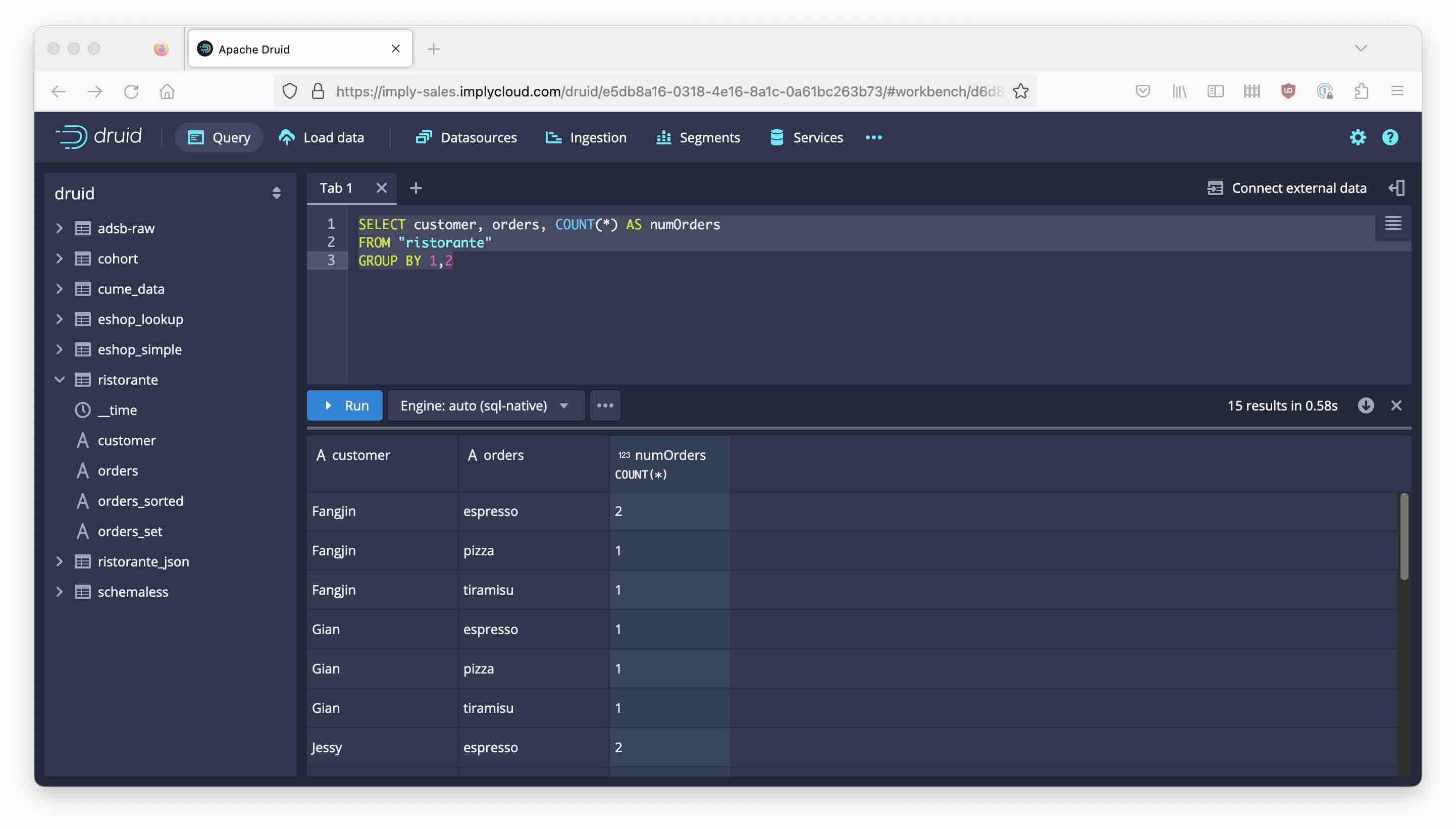
No surprises here. The MVD is unnested and the counts are broken down by item, as expected.
Quirks in multi-value filtering
Now let’s filter by one specific item.
SELECT customer, orders, COUNT(*) AS numOrders
FROM "ristorante"
WHERE orders = 'tiramisu'
GROUP BY 1,2
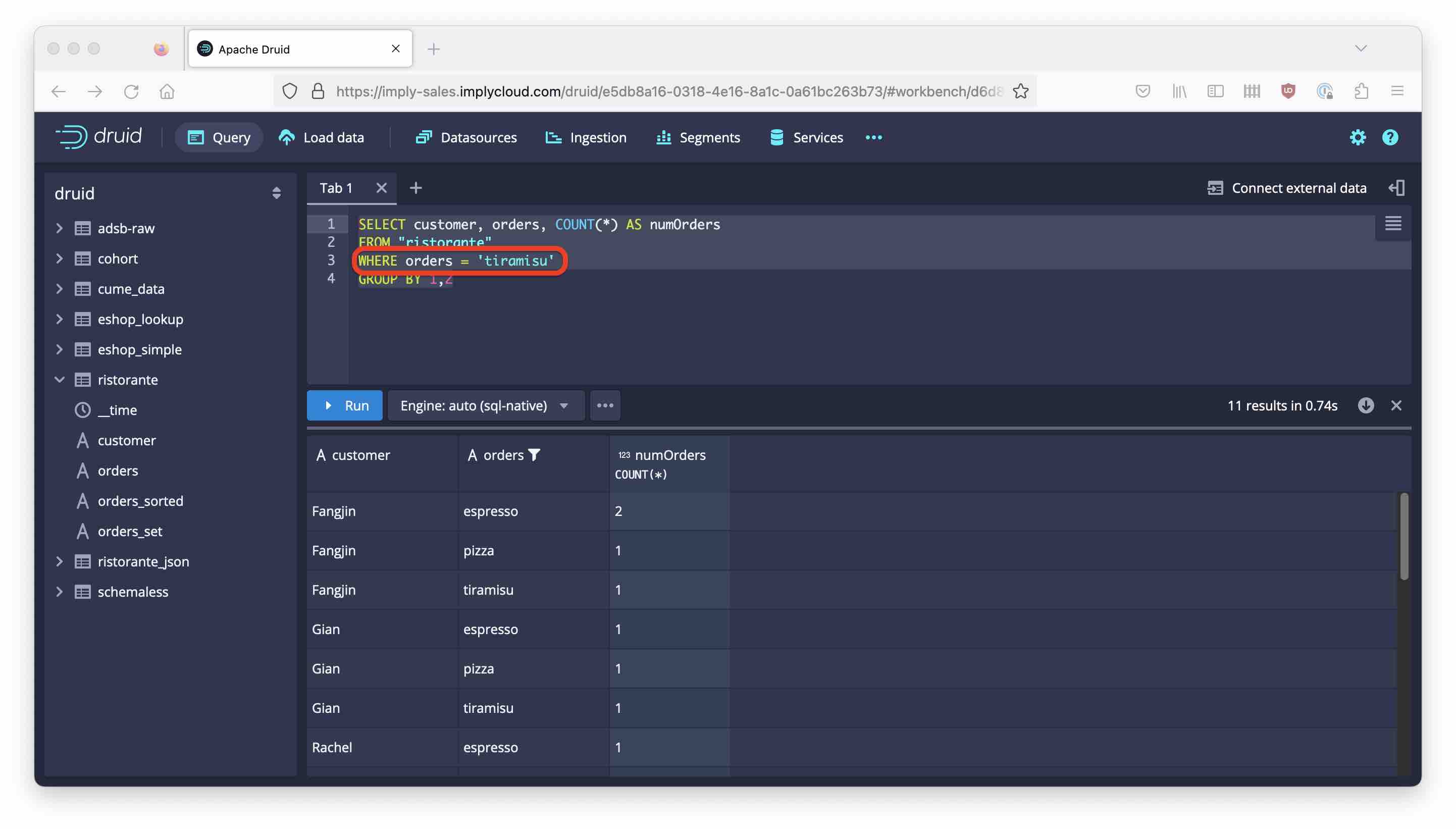
The result contains a lot of items that are definitely not Tiramisu! We got the filtering behavior from the plain query (without GROUP BY) and only after that the unnesting was applied!
Maybe if we try to filter after the grouping step, it would work?
SELECT customer, orders, COUNT(*) AS numOrders
FROM "ristorante"
GROUP BY 1,2
HAVING orders = 'tiramisu'
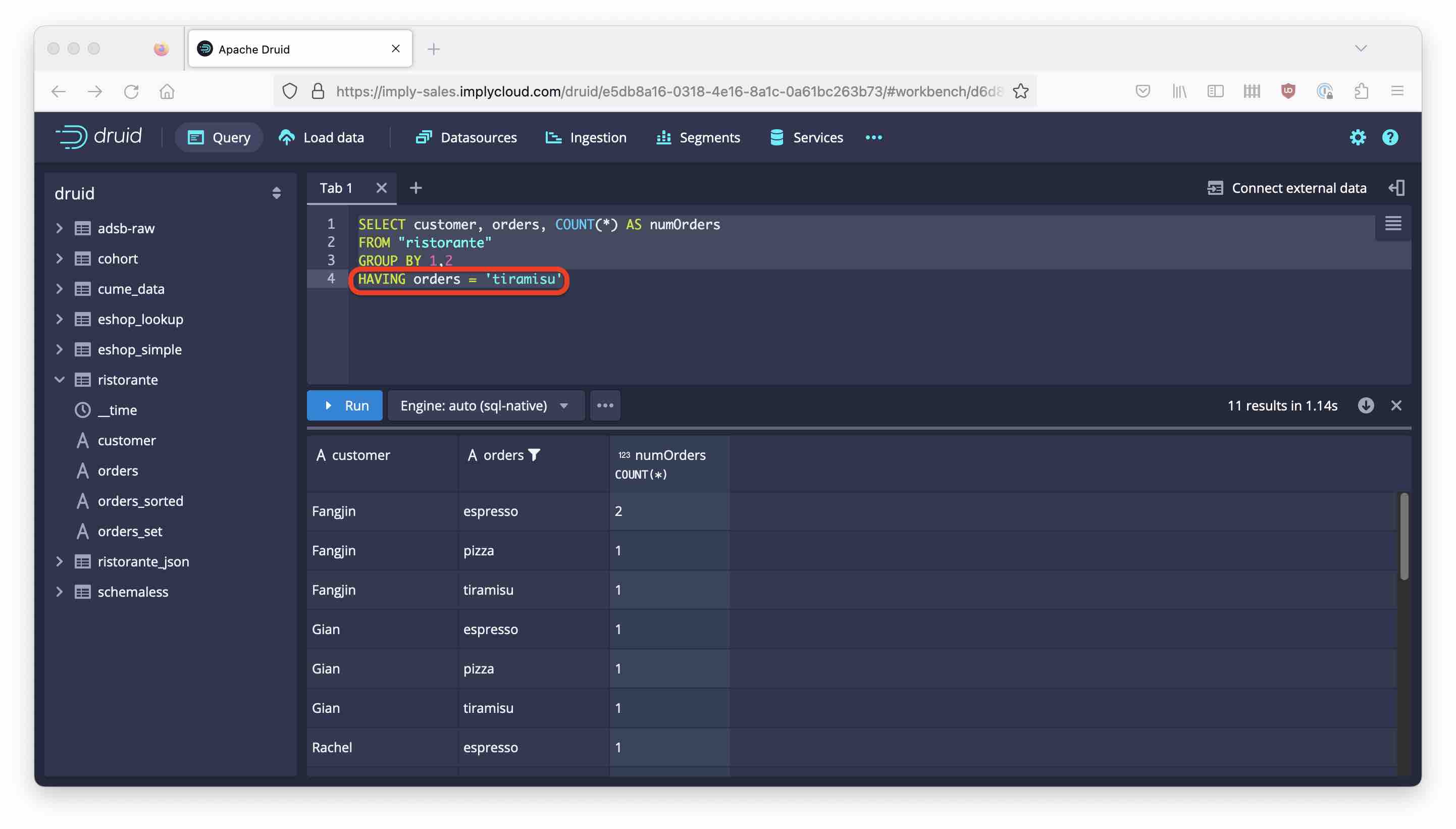
Alas, the result is the same. No matter how you write the filter, the query plan always selects whole rows of data as they are in the datasource. This is a common trap for the unwary, although the behavior is documented here for native queries, into which SQL queries are translated internally.
The same paragraph also mentions SQL multi-value functions. This is where the path to a solution lies.
Filtering multi-value strings, properly
The core to the solution is the MV_FILTER_ONLY function, which is applied to a multi-value field in the projection clause of the SELECT statement. Its first argument is the field that you want to filter on, the second argument is an array literal of the values that you want to keep.
Arrays are currently the red-headed stepchild of Druid data modeling, although this is about to change soon and there will be a lot more support for them. For now, you cannot declare an ARRAY column (MVDs are of type string). But you can define an array literal with the ARRAY constructor. There is also a set of multi-value functions that manipulate such ARRAYs, but that is another story for another time.
(The complementary function to MV_FILTER_ONLY, MV_FILTER_NONE, keeps only the values that are not contained in the array that you pass as the second argument.)
Let’s put together the query:
SELECT
customer,
MV_FILTER_ONLY(orders, ARRAY['tiramisu']) AS orderItem,
COUNT(*) AS numOrders
FROM "ristorante"
WHERE orders = 'tiramisu'
GROUP BY 1,2
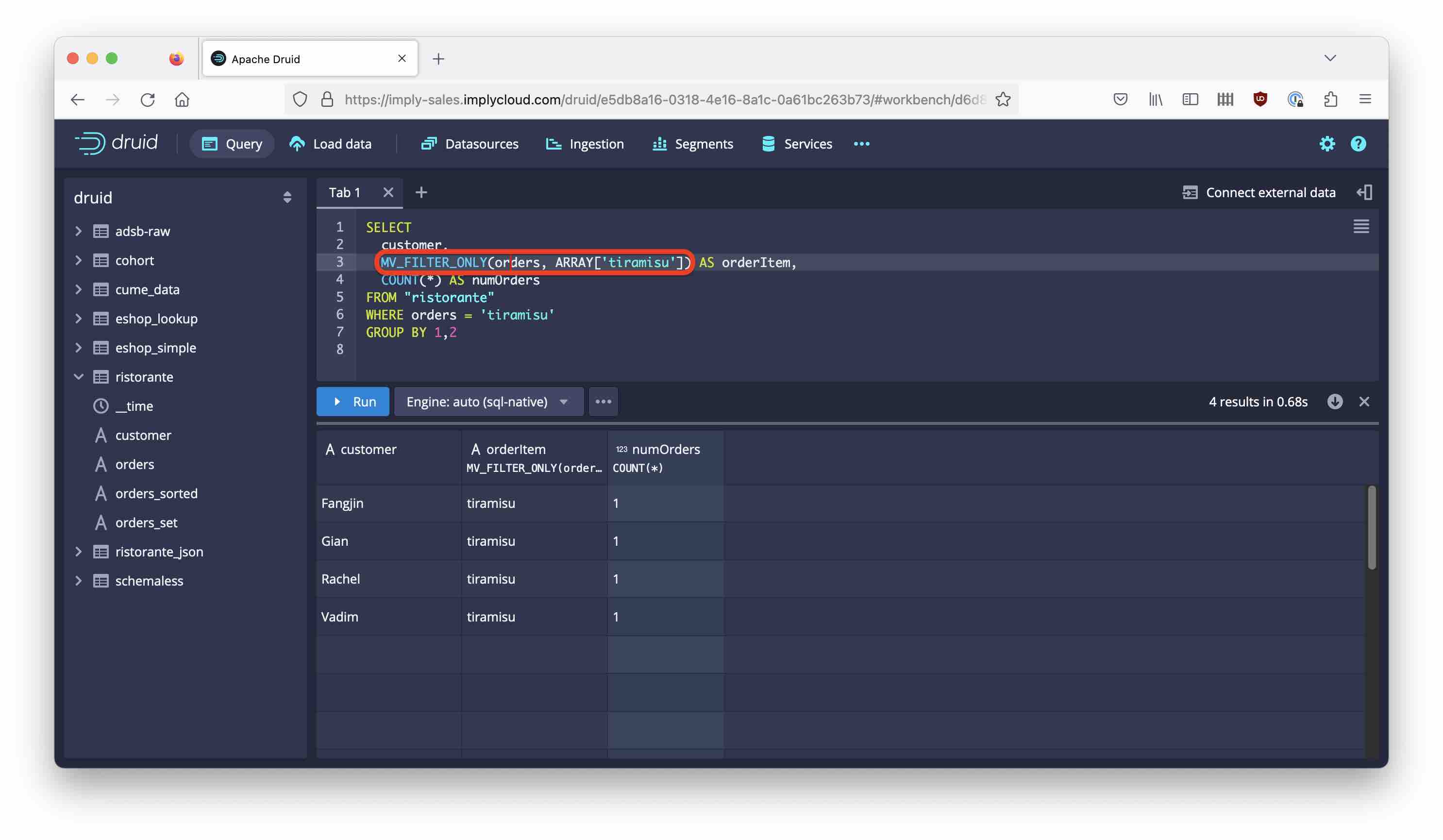
You might be thinking that we can do without the WHERE clause, now that the filter is applied in the projection. Let’s try it out:
SELECT
customer,
MV_FILTER_ONLY(orders, ARRAY['tiramisu']) AS orderItem,
COUNT(*) AS numOrders
FROM "ristorante"
GROUP BY 1,2
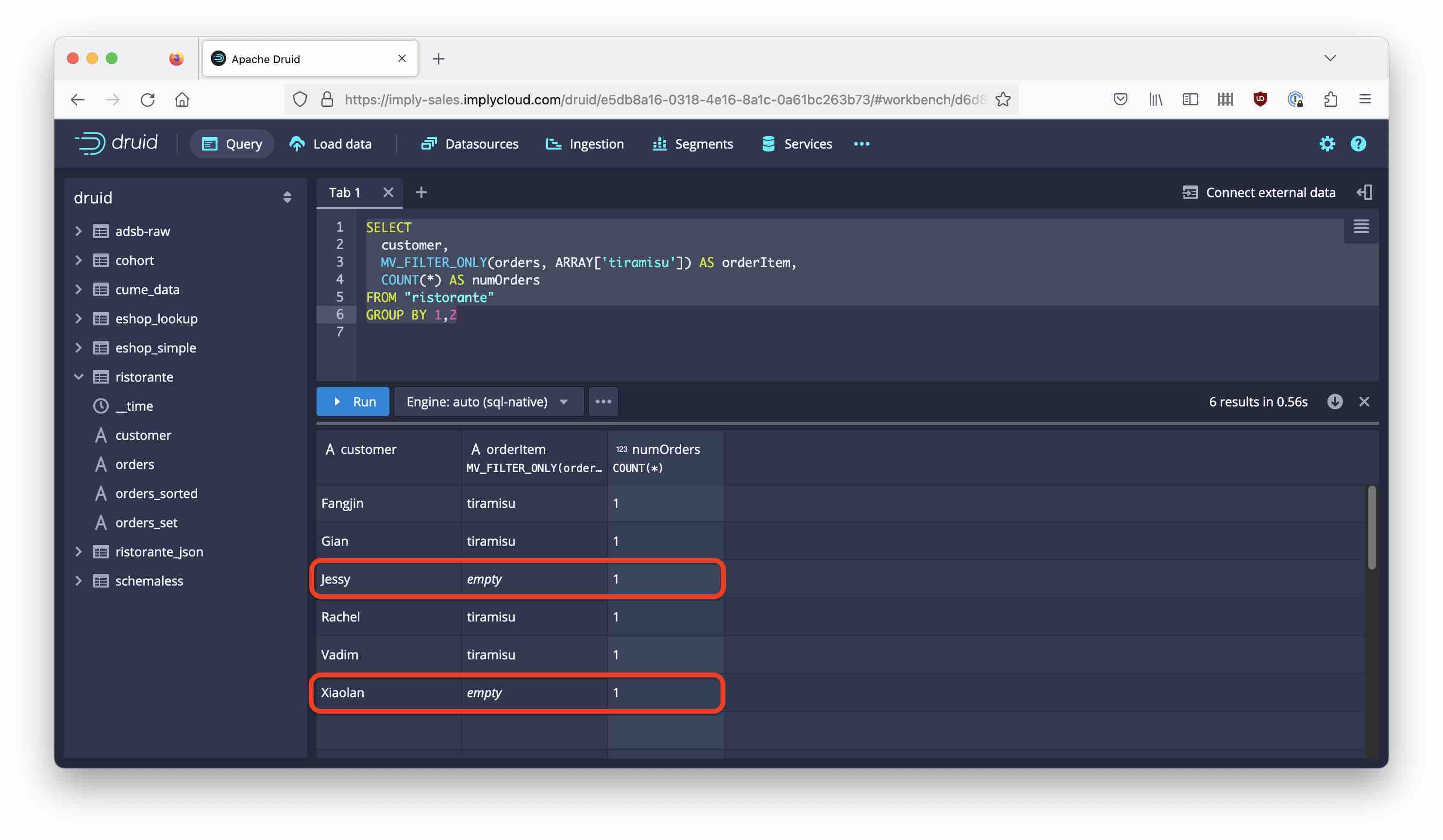
Unfortunately, now the result set has rows even for customers that didn’t order Tiramisu, and what is worse, they get a numOrders value of 1. You have to apply both filters in order to get the correct result.
More complex filters
What if we want to list the orders not for one, but for multiple items? Sure, you could write a query like
SELECT
customer,
MV_FILTER_ONLY(orders, ARRAY['espresso', 'tiramisu']) AS orderItem,
COUNT(*) AS numOrders
FROM "ristorante"
WHERE orders = 'tiramisu' OR orders = 'espresso'
GROUP BY 1,2
with a boolean condition in the WHERE clause. But there is a more elegant way, and it involves more MV_ functions. Instead of the OR condition, write this:
SELECT
customer,
MV_FILTER_ONLY(orders, ARRAY['espresso', 'tiramisu']) AS orderItem,
COUNT(*) AS numOrders
FROM "ristorante"
WHERE MV_OVERLAP(orders, ARRAY['espresso', 'tiramisu'])
GROUP BY 1,2
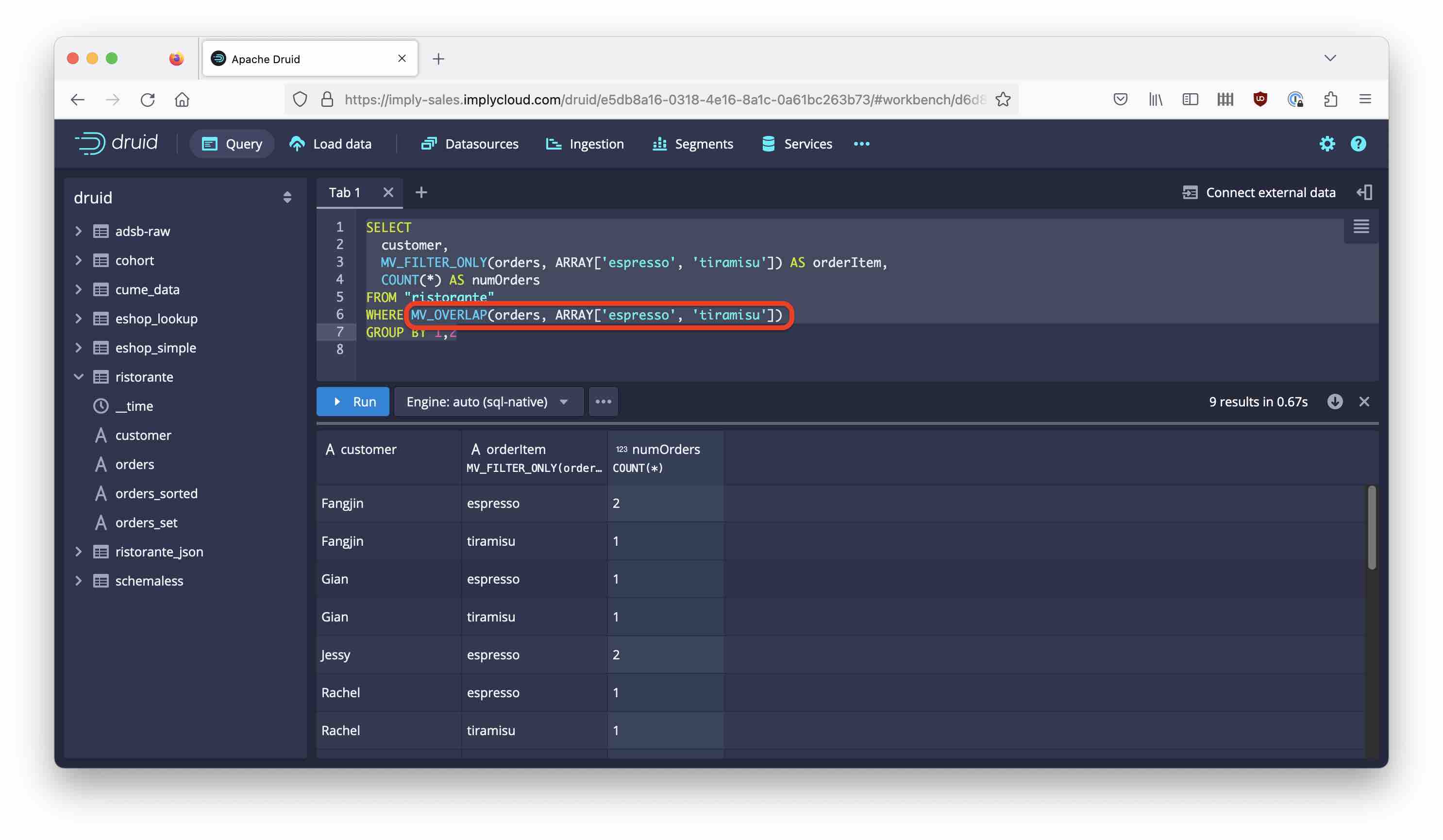
MV_OVERLAPreturns 1 when both array arguments have any elements in common, meaning it can be used to model anORcondition which is true if any of the filter elements is in the data column.- Likewise,
MV_CONTAINSreturns 1 if all elements of its second parameter array are contained within the first parameter, and can be used to model anANDcondition.
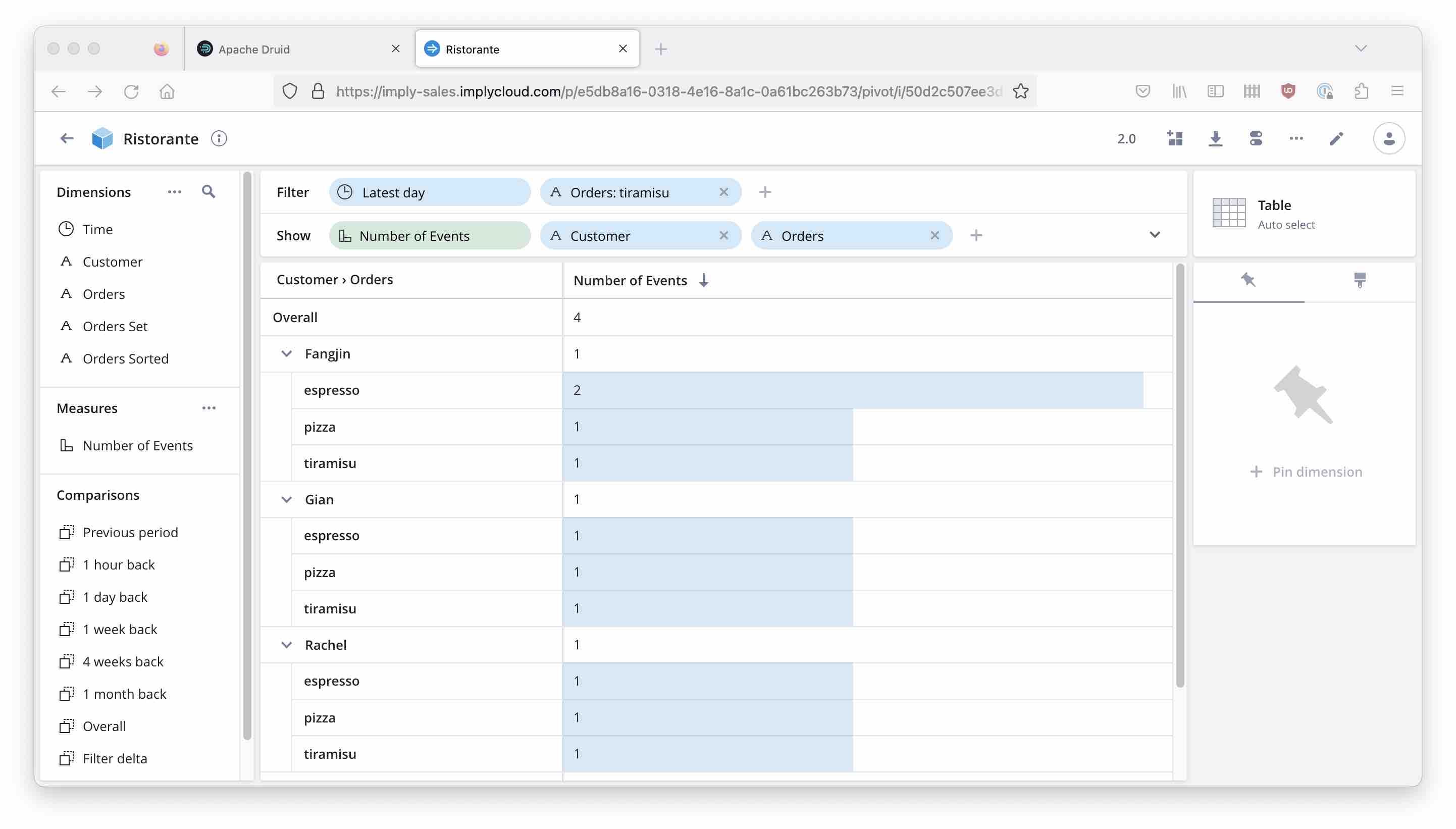
Visualizing it with Imply Pivot
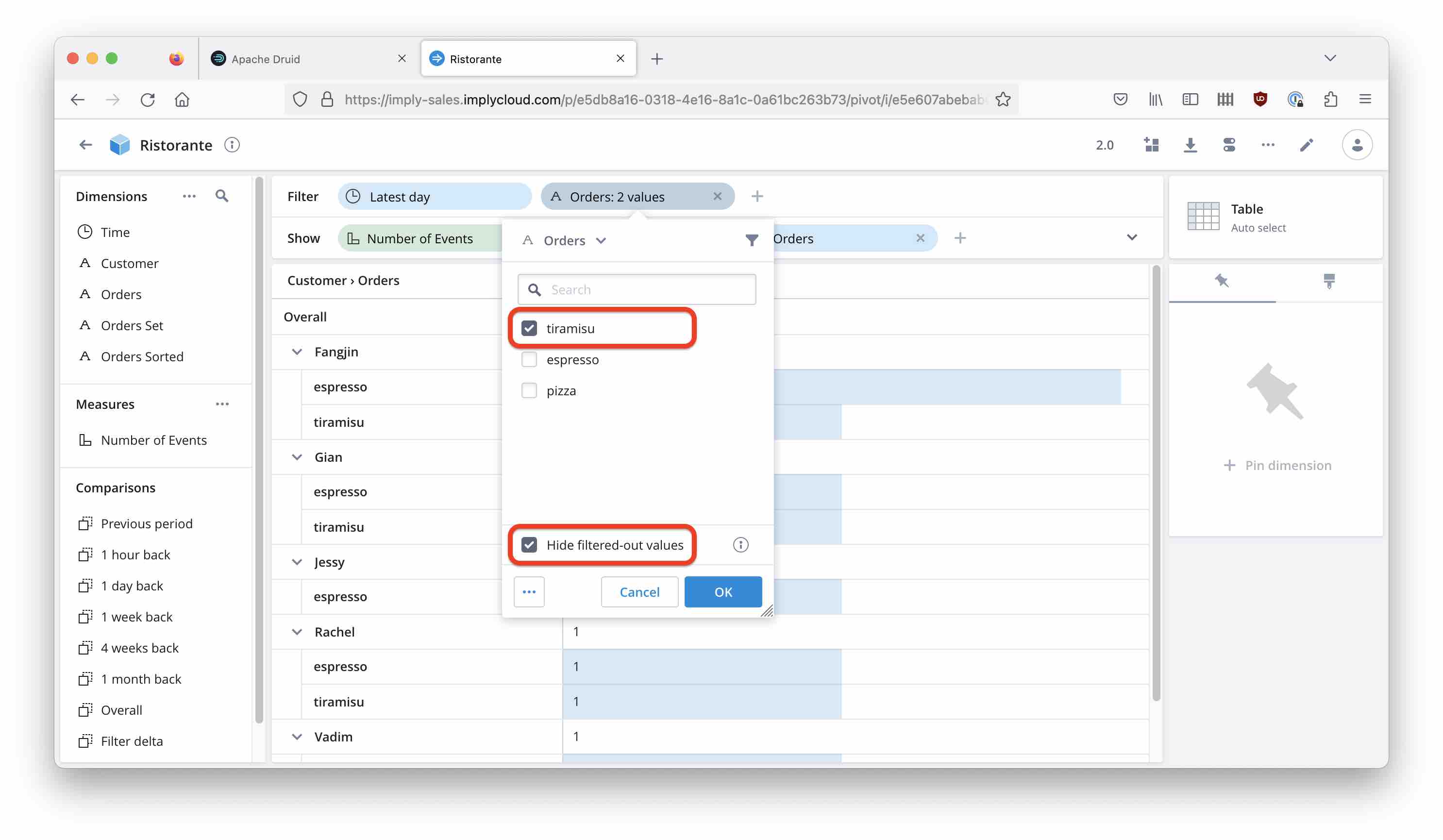
Imply Pivot now has an option to enable this strict filtering. If you filter by an MVD, there is an additional checkbox “Hide filtered-out values” that enables the behavior we just built manually with MV functions.
With the checkbox checked, we get the correct result:
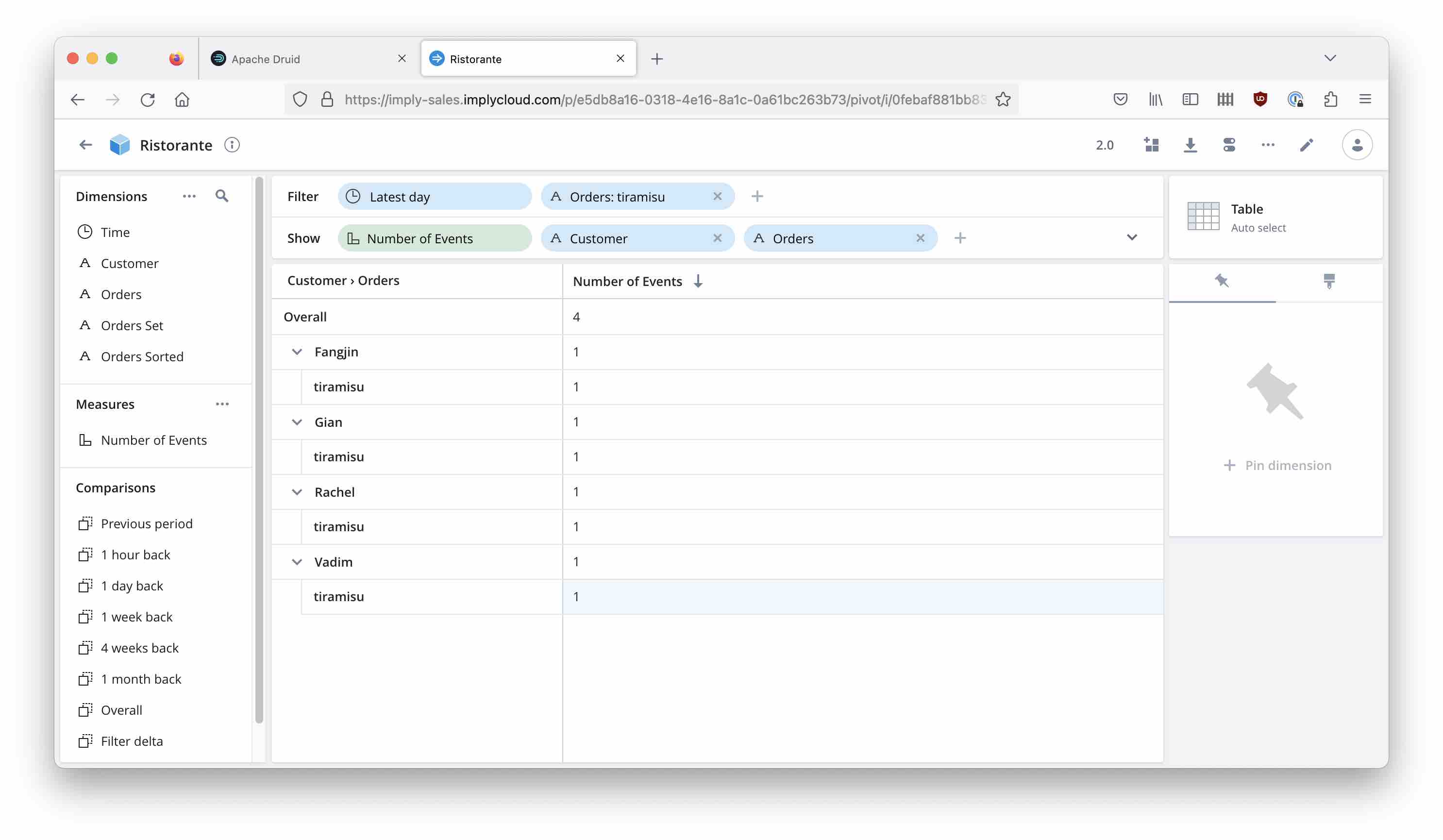
With the checkbox unchecked, we get the same result as in the beginning - all orders of all people that had Tiramisu:
Learnings
- Because of the way implicit unnesting works with Apache Druid, you may be surprised by the result when you filter and group by the same multi-value column.
- Strict filtering can be enabled using SQL multi-value functions.
MV_FILTER_ONLYandMV_FILTER_NONEare used in the projection clause to eliminate unwanted values.MV_CONTAINSandMV_OVERLAPare used in the filter clause to eliminate rows that have none of the wanted values at all, and would not be caught in the projection clause.- The two sets of functions usually have to be used together to obtain correct results.
- Imply Pivot is able to apply this logic transparently when querying one of its data cubes.