Connecting Apache Druid to Kafka with TLS authentication
We’ve looked at connecting Apache Druid to a secure Kafka cluster before. In that article, I used a Confluent Cloud cluster with API key and secret, which is basically username + password authentication.
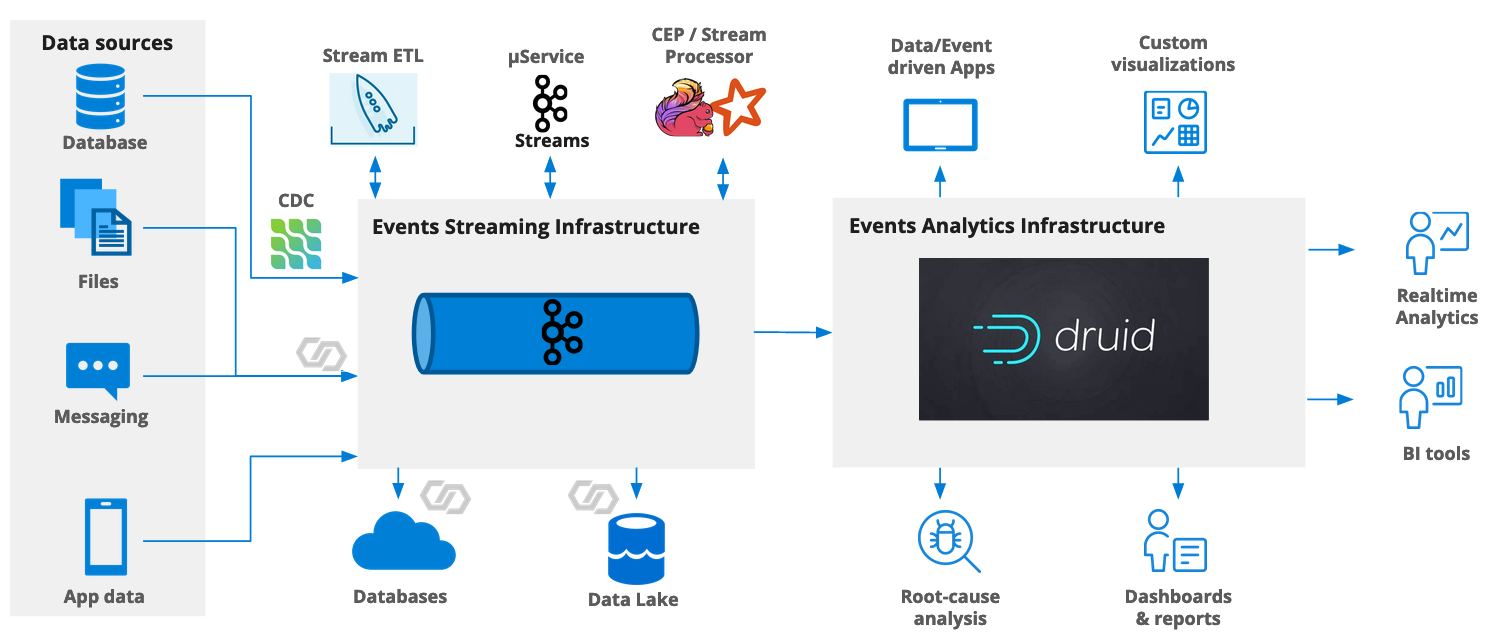
Kafka also supports mutual TLS (mTLS) authentication. In that case keys and certificates need to be stored on the Druid cluster that wants to connect to Kafka, and the ingestion spec needs to reference these data.
In this tutorial, I am going to show how to connect Druid to Kafka using mTLS. I am using an Aiven Kafka cluster because Aiven supports mTLS secured Kafka out of the box as the default. Aiven’s documentation describes how to set up a Kafka cluster with Aiven. For this tutorial, the smallest plan (Startup-2) is enough.
Setting up the Keystore and Truststore
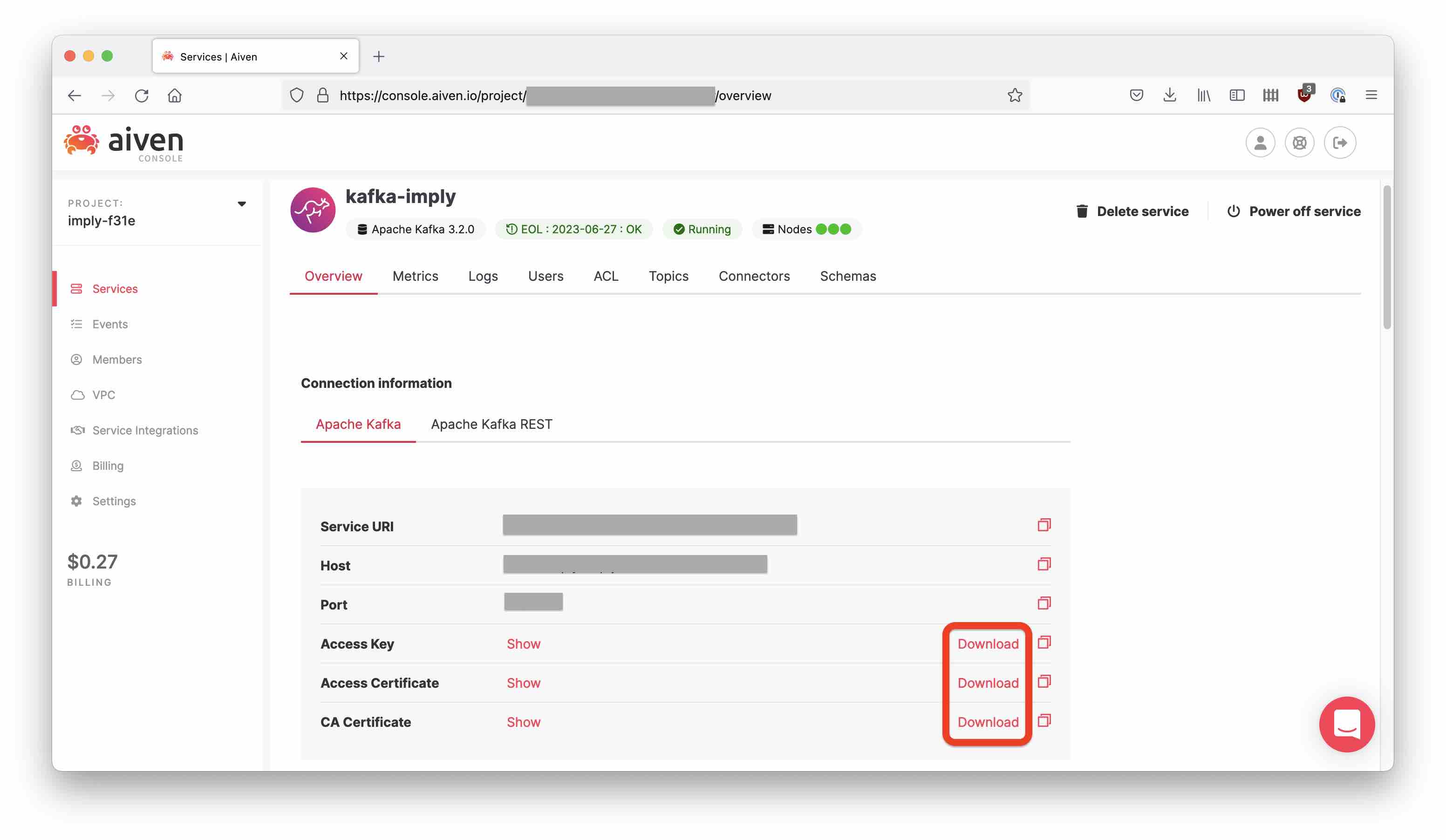
An mTLS secured Kafka service will offer you three files to download:
- the access key
service.key - the access certificate
service.cert - the CA certificate
ca.pem.
Download all three into a new directory aiven-tls:
We will have to convert those files to Java keystore format in order to use them with Druid. This is explained in detail in this StackOverflow entry.
Run the following commands to create a Java keystore and truststore file:
openssl pkcs12 -inkey service.key -in service.cert -export -out aiven_keystore.p12 -certfile ca.pem
keytool -importkeystore -destkeystore aiven_keystore.jks -srckeystore aiven_keystore.p12 -srcstoretype pkcs12
keytool -import -alias aivenCert -file ca.pem -keystore aiven_cacerts.jks
Choose changeit as the password in both cases when keytool asks for a new password.
This will leave you with two files aiven_keystore.jks and aiven_cacerts.jks.
Generating Data
I am using Aiven’s Pizza simulator to create a Kafka topic and fill it with some data. This blog describes in detail how to set up the cluster, create a topic, and generate fake pizza order data to fill up the topic.
Enable kafka.auto_create_topics_enable in the advanced configuration settings of your cluster. Then, clone the data simulator repository and make sure you have all necessary dependencies installed.
Run the command
python3 main.py --security-protocol SSL --cert-folder ~/aiven-tls --host <your Kafka service host> --port <your Kafka service port> --topic-name pizza --nr-messages 100 --max-waiting-time 10
using the cert-folder where you downloaded the certificate files in the first step.
Setting up Druid
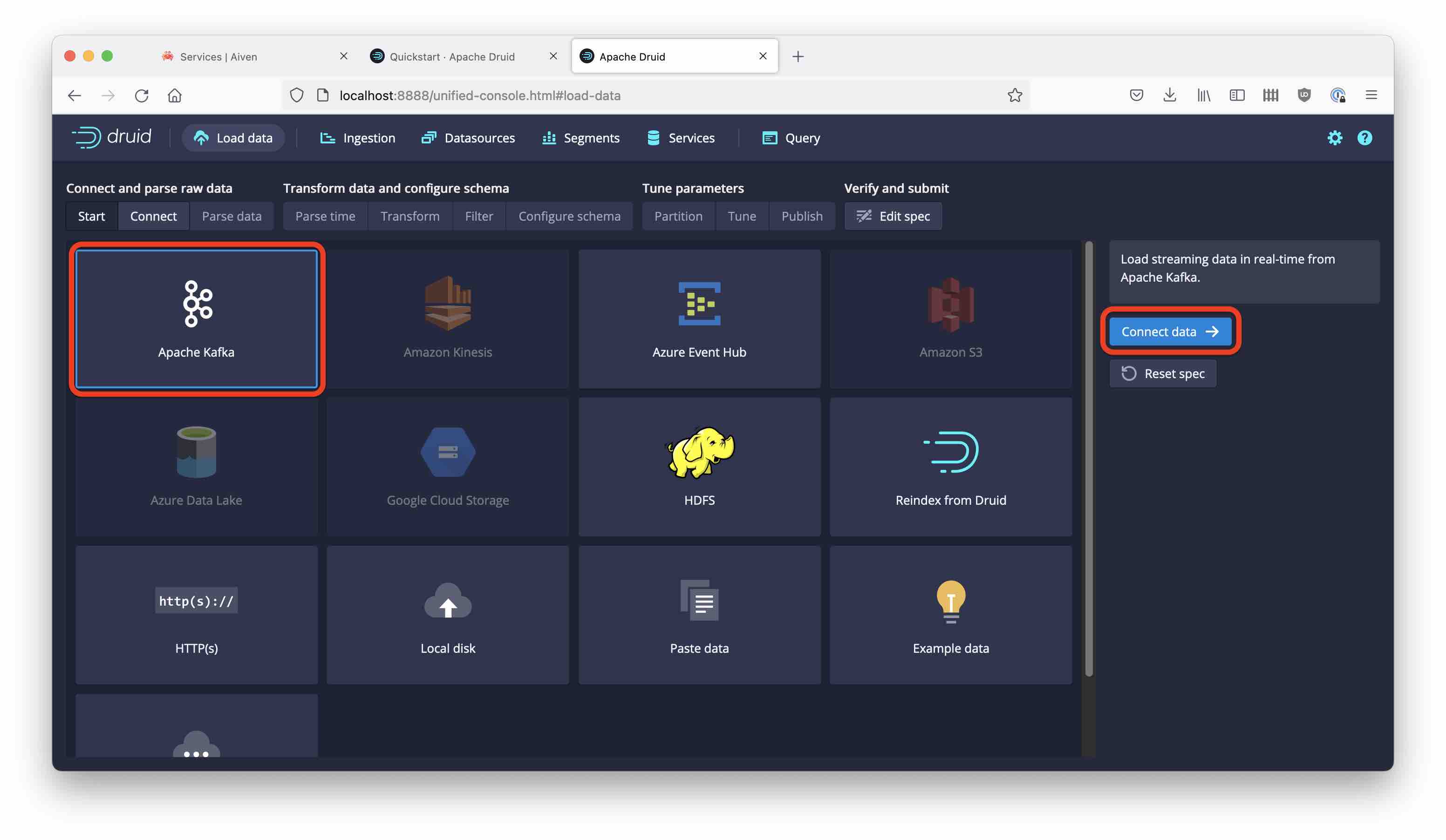
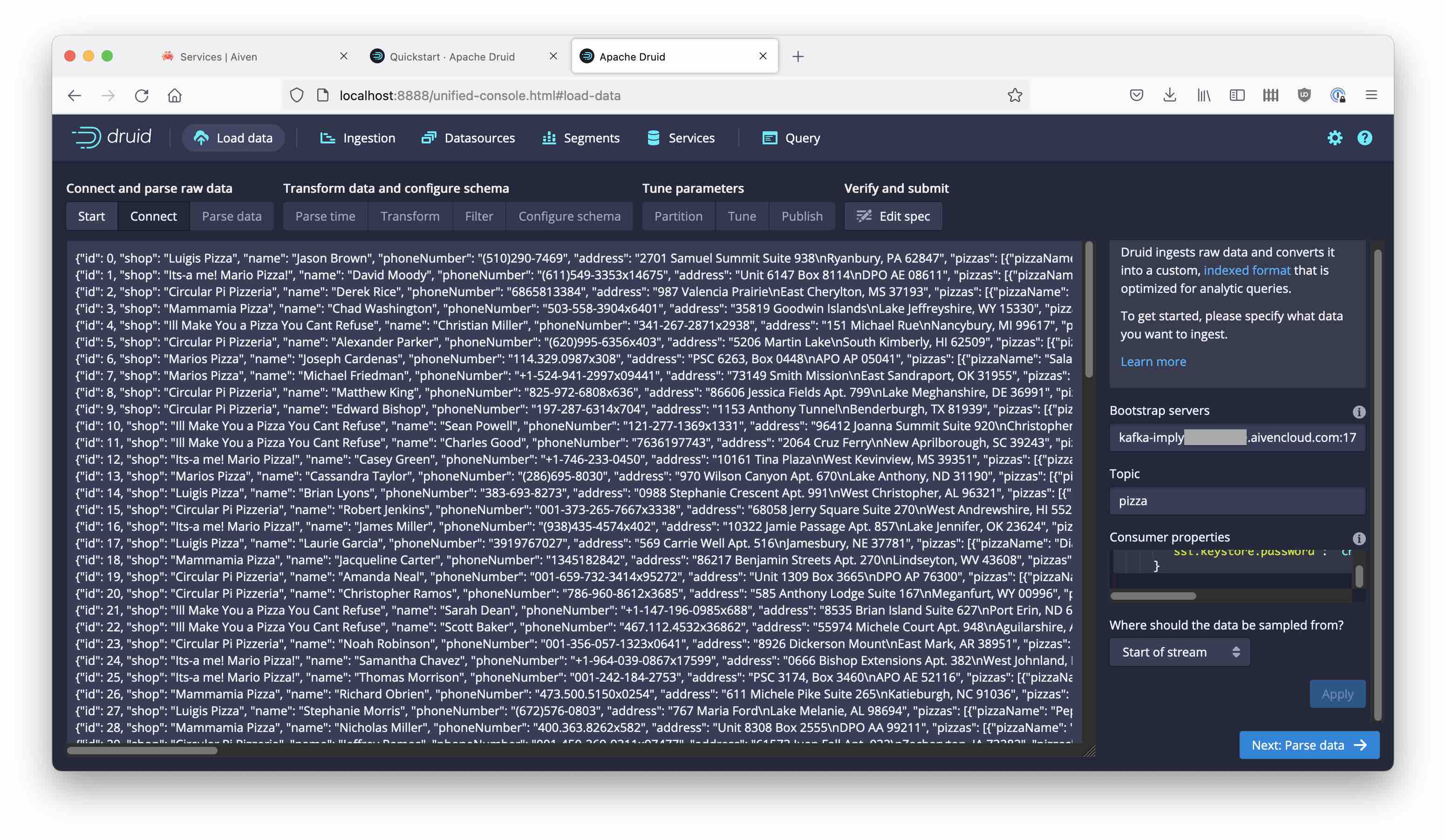
Download the latest Druid release and follow the quickstart instructions. Go to the Druid console at localhost:8888 and start the Load data wizard. Select Kafka and proceed to enter the connection details:
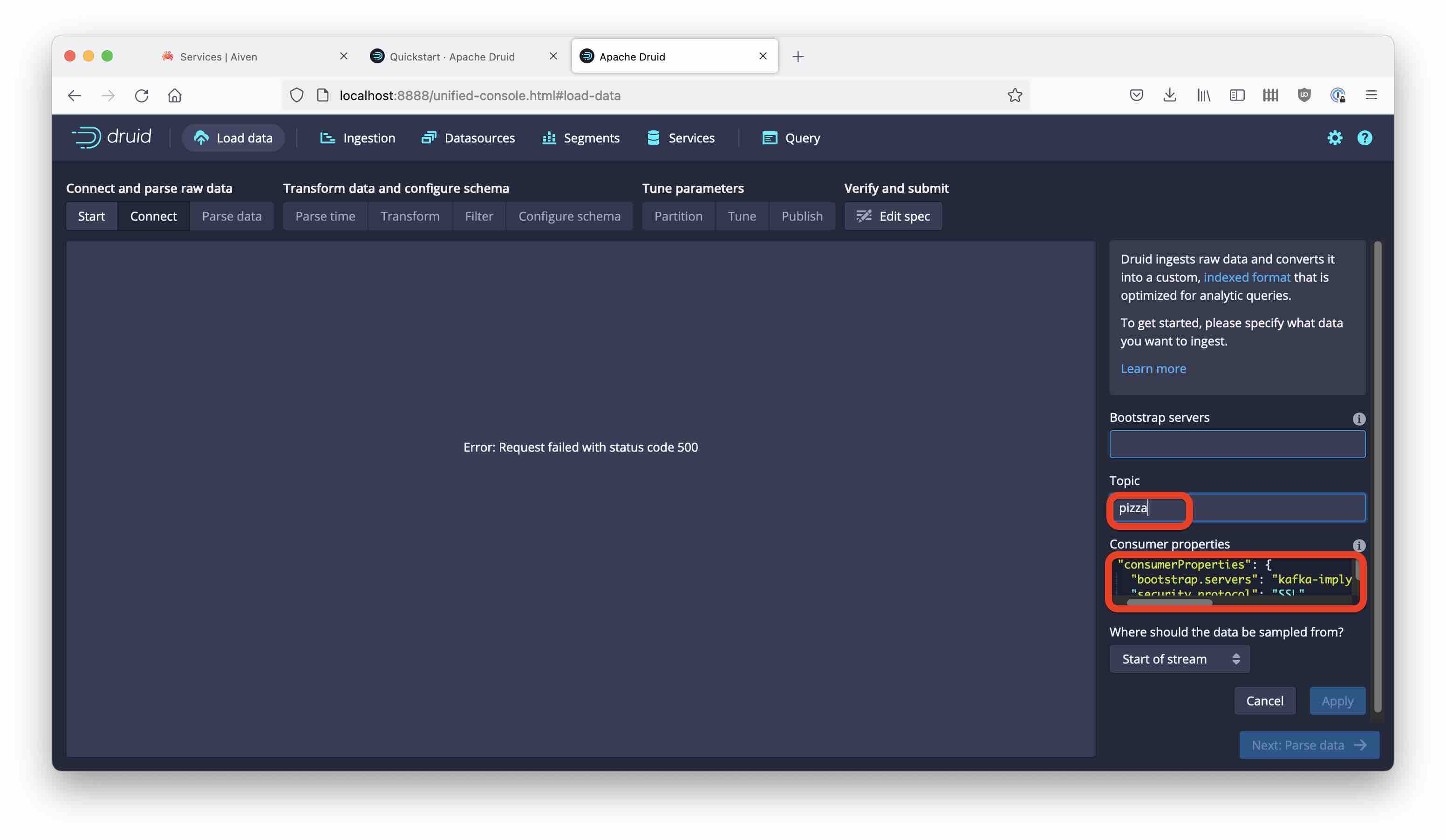
Create a consumer properties snippet to reference the keystore and truststore files you created earlier. Here is a template, you need to fill in the correct path and host:port.
{
"bootstrap.servers": "<your Kafka service host + port>",
"security.protocol": "SSL",
"ssl.truststore.location": "<your home directory>/aiven-tls/aiven_cacerts.jks",
"ssl.truststore.password": "changeit",
"ssl.keystore.location": "<your home directory>/aiven-tls/aiven_keystore.jks",
"ssl.keystore.password": "changeit"
}
Copy the snippet into the Consumer properties box and enter pizza as the topic name:
As you continue from here, you should see the data coming in:
Proceed all the way to the schema definition:
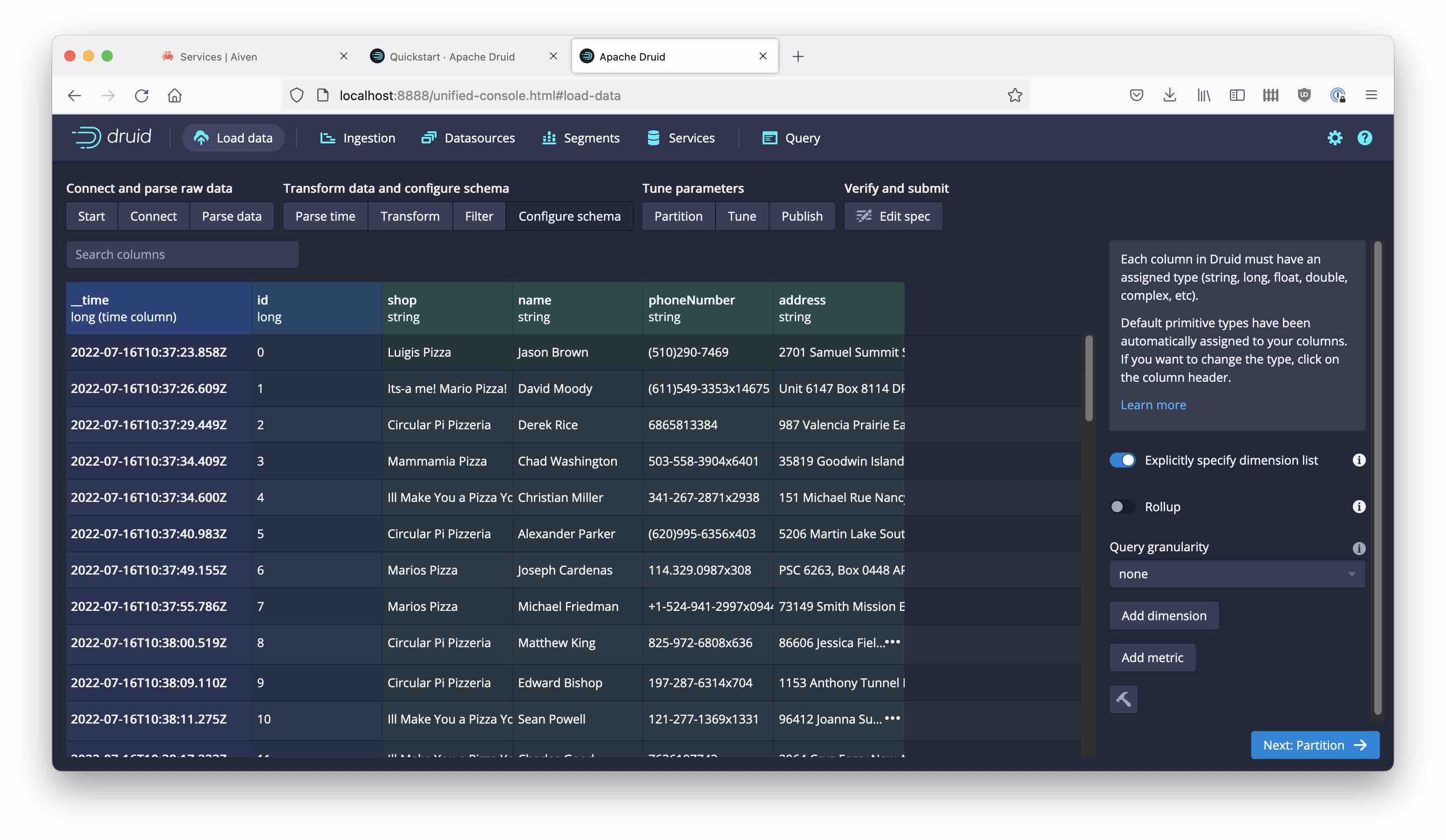
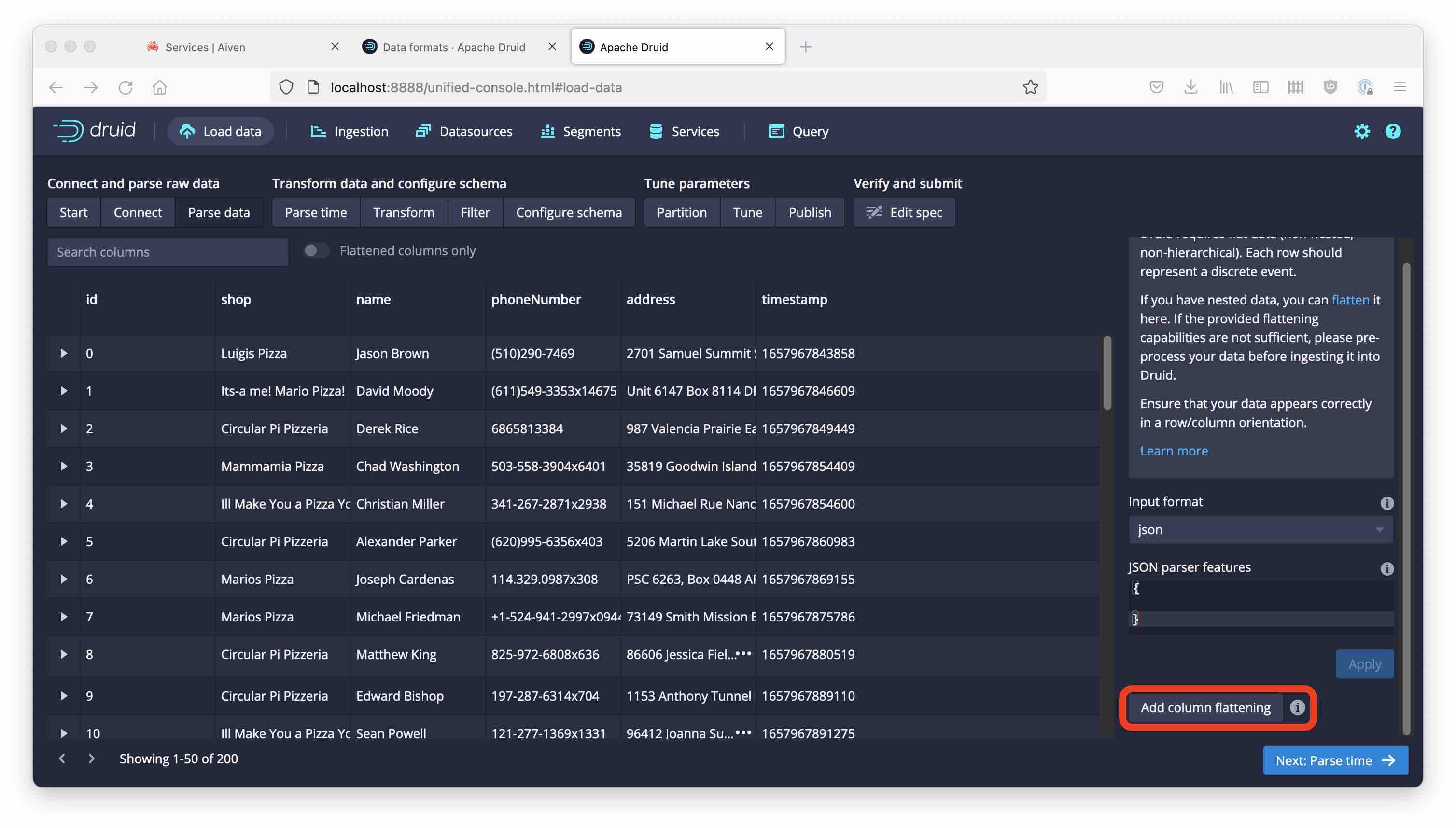
But what is this?! All the order details seem to be missing.
Here is a sample of the data the simulator generates:
{'id': 91, 'shop': 'Its-a me! Mario Pizza!', 'name': 'Brandon Schwartz', 'phoneNumber': '305-351-2631', 'address': '746 Chelsea Plains Suite 656\nNew Richard, DC 42993', 'pizzas': [{'pizzaName': 'Diavola', 'additionalToppings': ['salami', 'green peppers', 'olives', 'garlic', 'strawberry']}, {'pizzaName': 'Salami', 'additionalToppings': ['tomato', 'olives']}, {'pizzaName': 'Salami', 'additionalToppings': ['banana', 'olives', 'artichokes', 'onion', 'banana']}, {'pizzaName': 'Mari & Monti', 'additionalToppings': ['olives', 'olives']}, {'pizzaName': 'Margherita', 'additionalToppings': ['mozzarella', 'tuna', 'olives']}, {'pizzaName': 'Mari & Monti', 'additionalToppings': ['pineapple', 'pineapple', 'ham', 'olives', 'salami']}], 'timestamp': 1657968296752}
There’s a lot of details in nested structures: pizzas is a JSON array of objects that each have a pizzaName and a list of additionalToppings.
Handling Nested Data
For now you have to extract individual fields using a flattenSpec. Customers of Imply can take advantage of native handling of nested data.
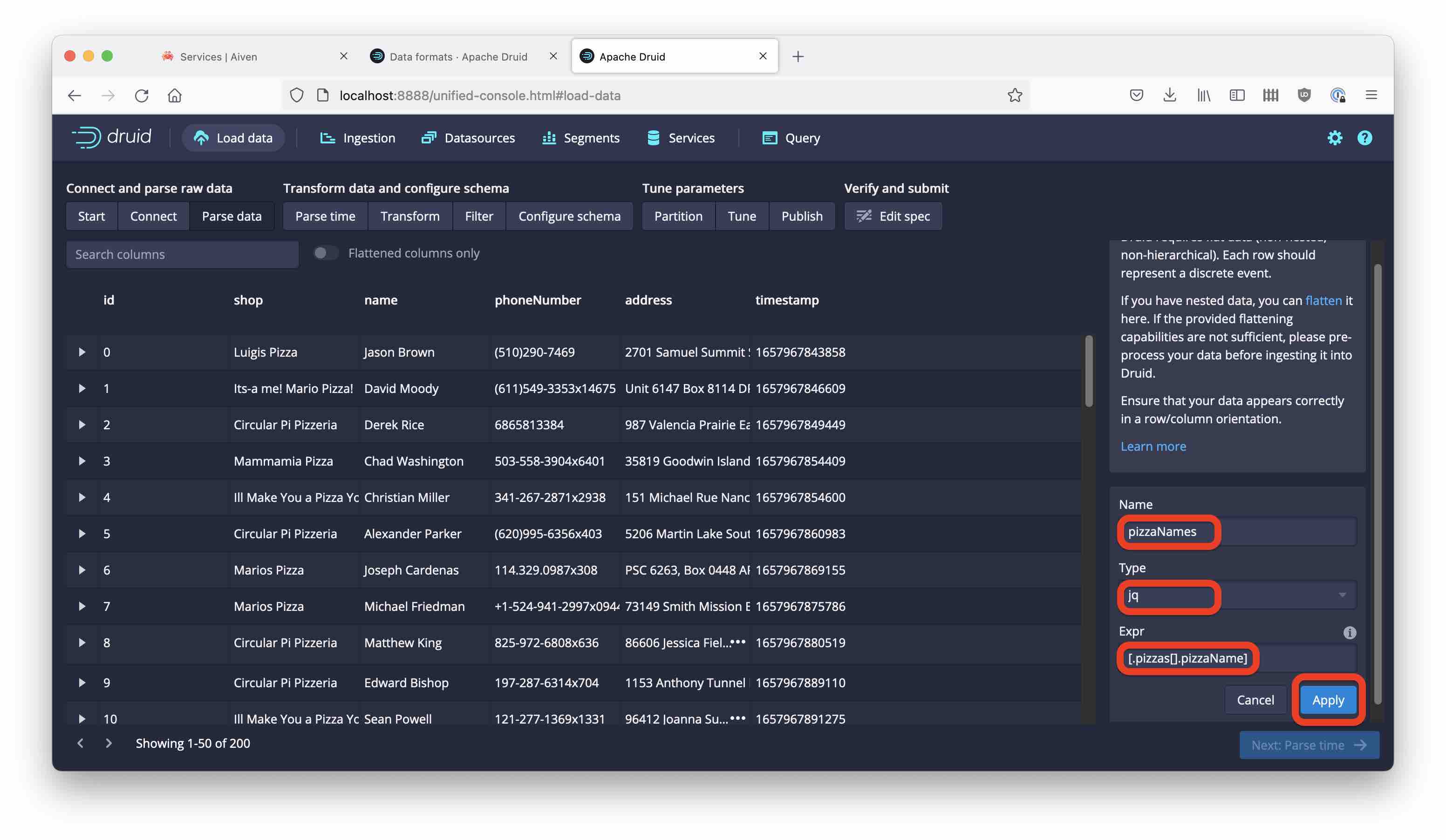
Let’s extract the pizza names as a multi-value dimension. Go back to the Parse data step and add a flattening:
Select
pizzaNamesfor Namejqfor Type- for Expr, enter:
[.pizzas[].pizzaName]
Kick off the ingestion and look at the data after a while:
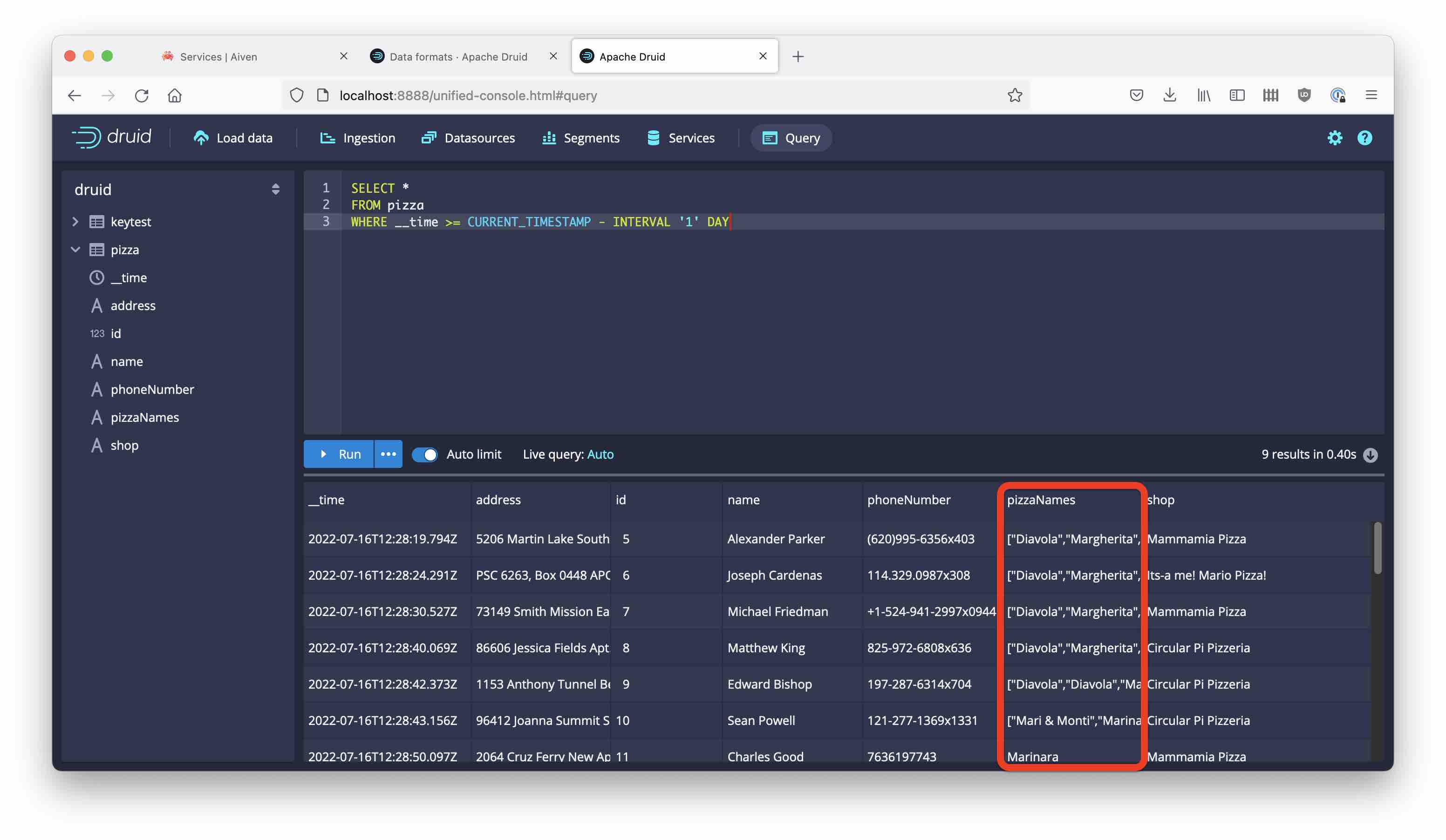
The pizza names are all there. And just like that, we have integrated with Aiven’s mTLS secured Kafka service!
Learnings
- Druid can easily connect to an mTLS authenticated Kafka service.
- You may need to use Java utilities to convert keys and certificates into JKS format.
- While Imply users can ingest nested JSON data natively, open source Druid offers powerful flattening capabilities that can utilize
jqsyntax.