Druid 28 Sneak Peek: Ingesting Multiple Kafka Topics into One Datasource

Apache Druid has the concept of supervisors that orchestrate ingestion jobs and handle data handoff and failure recovery. Per datasource, you can have exactly one supervisor.
Until recently, that meant that one datasource could only ingest data from one stream. But many of my customers asked whether it would be possible to multiplex several streams into populating one datasource. With Druid 28, this becomes possible!
In this quick tutorial, you will learn how to utilize the new options in Kafka ingestion so as to stream multiple topics into one Druid datasource. You will need:
- a Druid 28 preview build (see below)
- any Kafka installation
- I am using Francesco’s pizza simulator for generating test data.
Building the distribution
You can use the 30 day free trial of Imply’s Druid release which already contains the new features. Documentation is also available.
But if you want to build the open source version:
Clone the Druid repository, check out the 28.0.0 branch, and build the tarball:
git clone https://github.com/apache/druid.git
cd druid
git checkout 28.0.0
mvn clean install -Pdist -DskipTests
Then follow the instructions to locate and install the tarball, and start Druid. Make sure you are loading the Kafka indexing extension. (It is included in the quickstart but not by default in the Docker image.)
Generating test data
I am assuming that you are running Kafka locally on the standard port and that you have enabled auto topic creation.
Clone the simulator repository, change to the simulator directory and run three instances of pizza delivery:
python3 main.py --host localhost --port 9092 --topic-name pizza-mario --max-waiting-time 5 --security-protocol PLAINTEXT --nr-messages 0 >/dev/null &
python3 main.py --host localhost --port 9092 --topic-name pizza-luigi --max-waiting-time 5 --security-protocol PLAINTEXT --nr-messages 0 >/dev/null &
python3 main.py --host localhost --port 9092 --topic-name my-pizza --max-waiting-time 5 --security-protocol PLAINTEXT --nr-messages 0 >/dev/null &
If you have set up Kafka differently, you may have to modify these instructions.
Connecting Druid to the streams
Navigate your browser to the Druid GUI (in the quickstart, this is http://localhost:8888), and start configuring a streaming ingestion:
Choose Kafka as the input source. Note how there is a new option topicPattern in the connection settings:
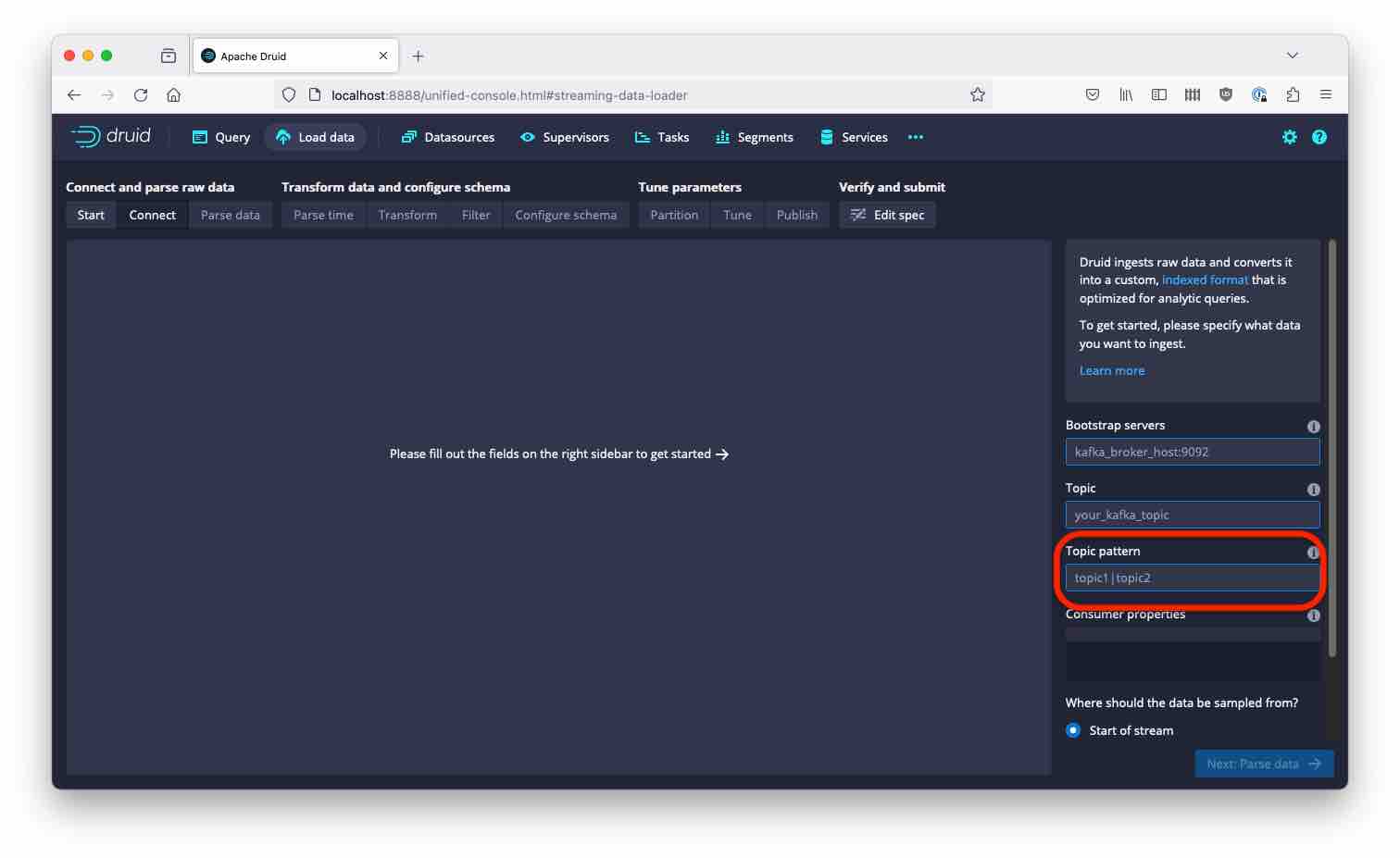
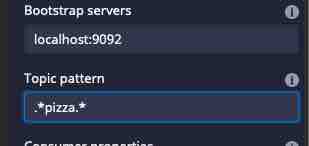
This is a regular expression that you can specify in place of the topic name. Let’s try to gobble up all our pizza related topics by setting the pattern to “pizza”:

Oh, this didn’t work as expected. But the documentation and bubble help show us the solution: The topic pattern has to match the entire topic name. So, the above expression actually matches like the regular expression ^pizza$.
Armed with this knowledge, let’s correct the pattern:
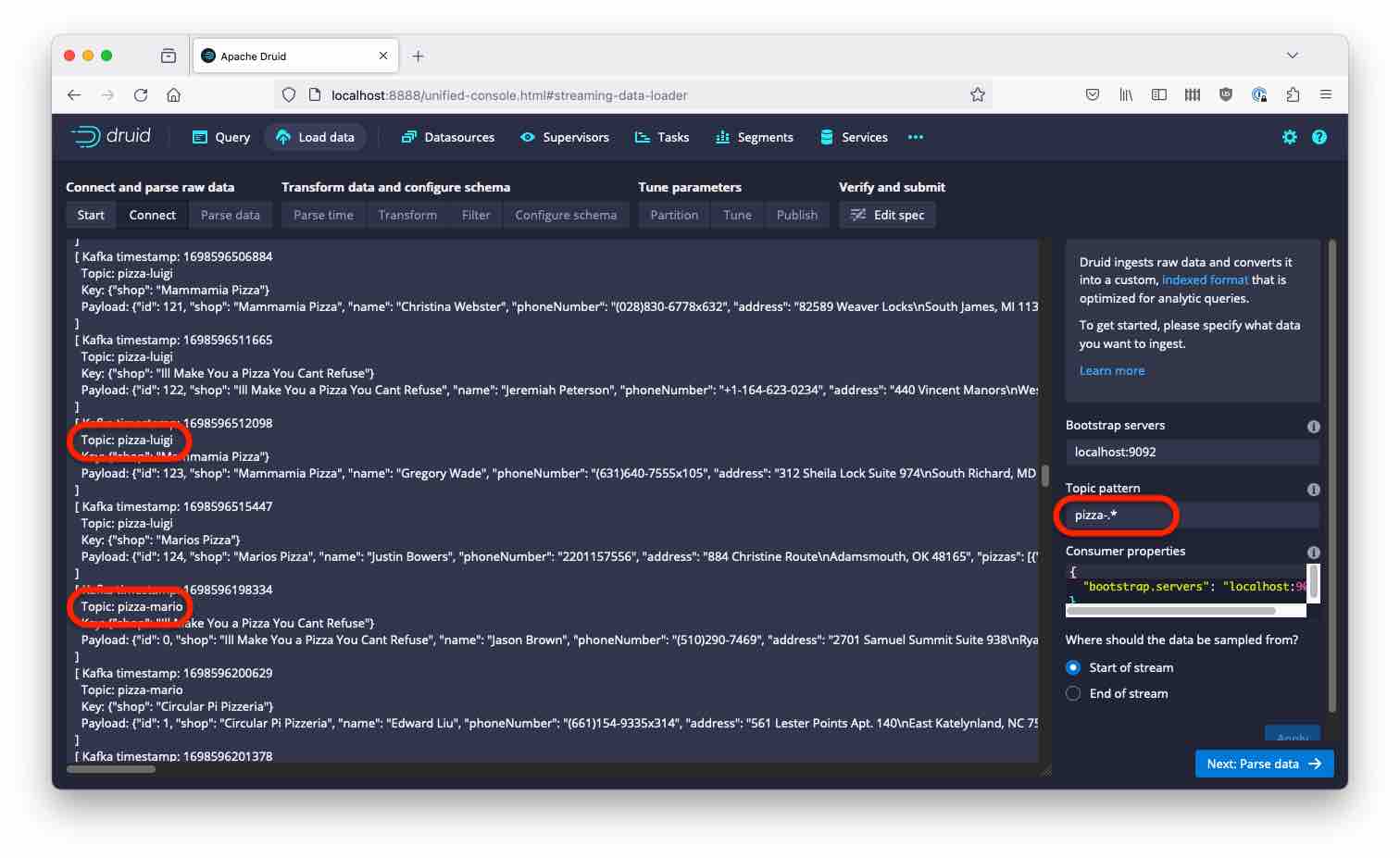
This matches all topic names that start with “pizza-“.
Building the data model
Let’s have a look at the Parse data screen. Among the Kafka metadata, there is a new field containing the source topic for each row of data. The default column name is kafka.topic but this is configurable in the Kafka metadata settings on the right hand side:
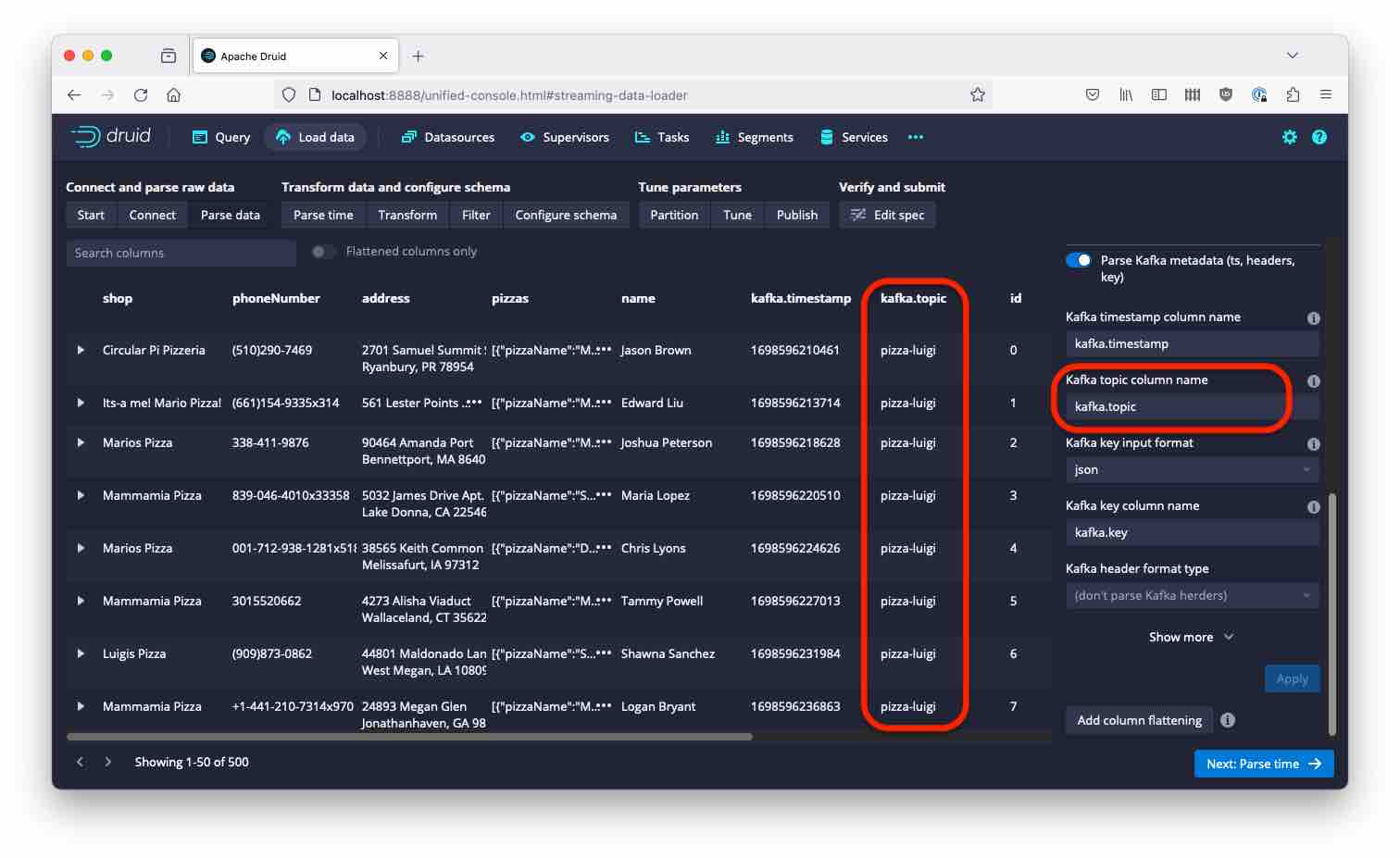
Proceed to the final data model - the topic name is automatically included as a string column:
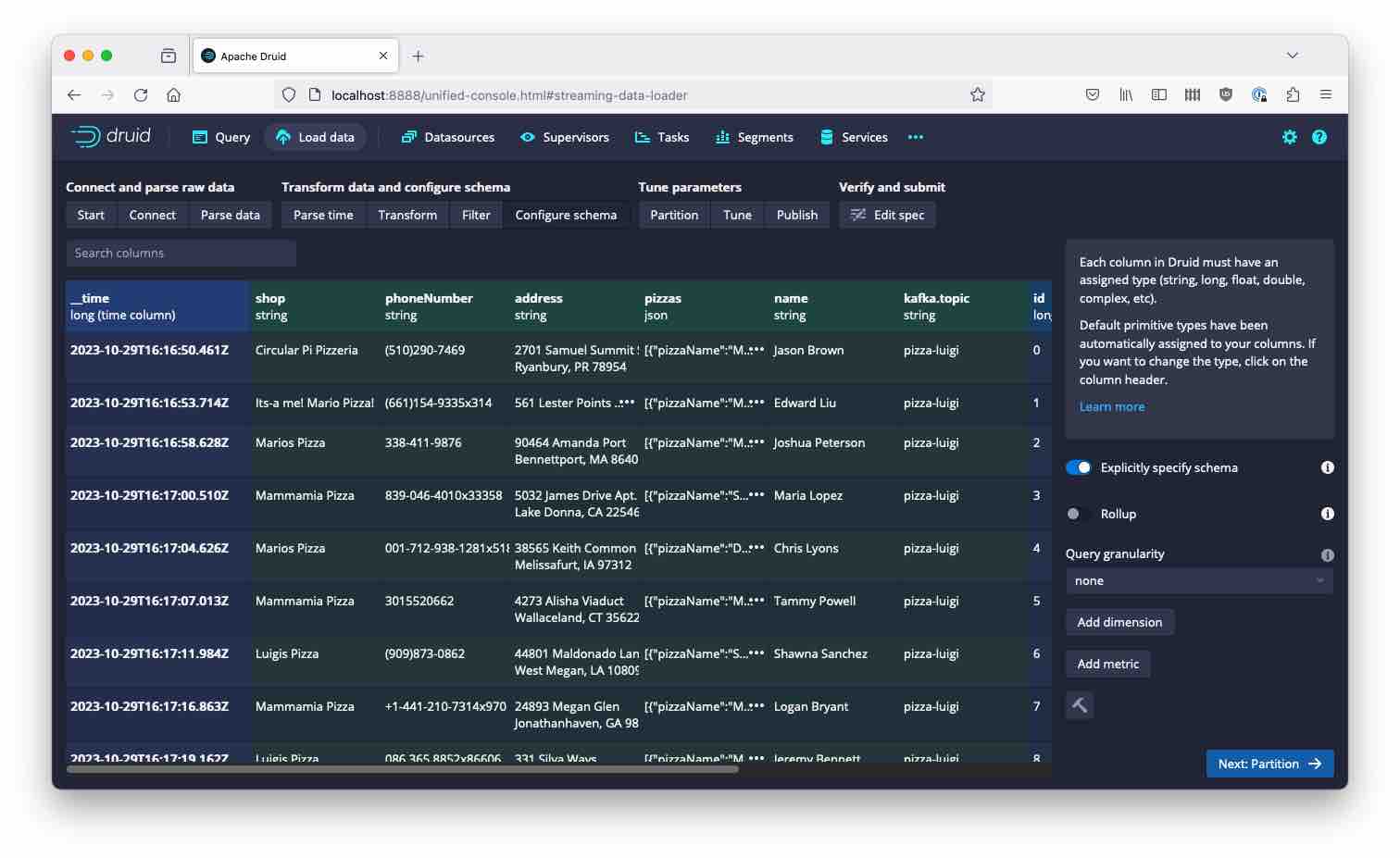
Before kicking off the ingestion job, you may want to review and edit the datasource name

because by default, the datasource name is derived from the topic pattern and may contain a lot of special characters.
Once the supervisor is running, you should see data coming in from both the pizza-mario and pizza-luigi topics:
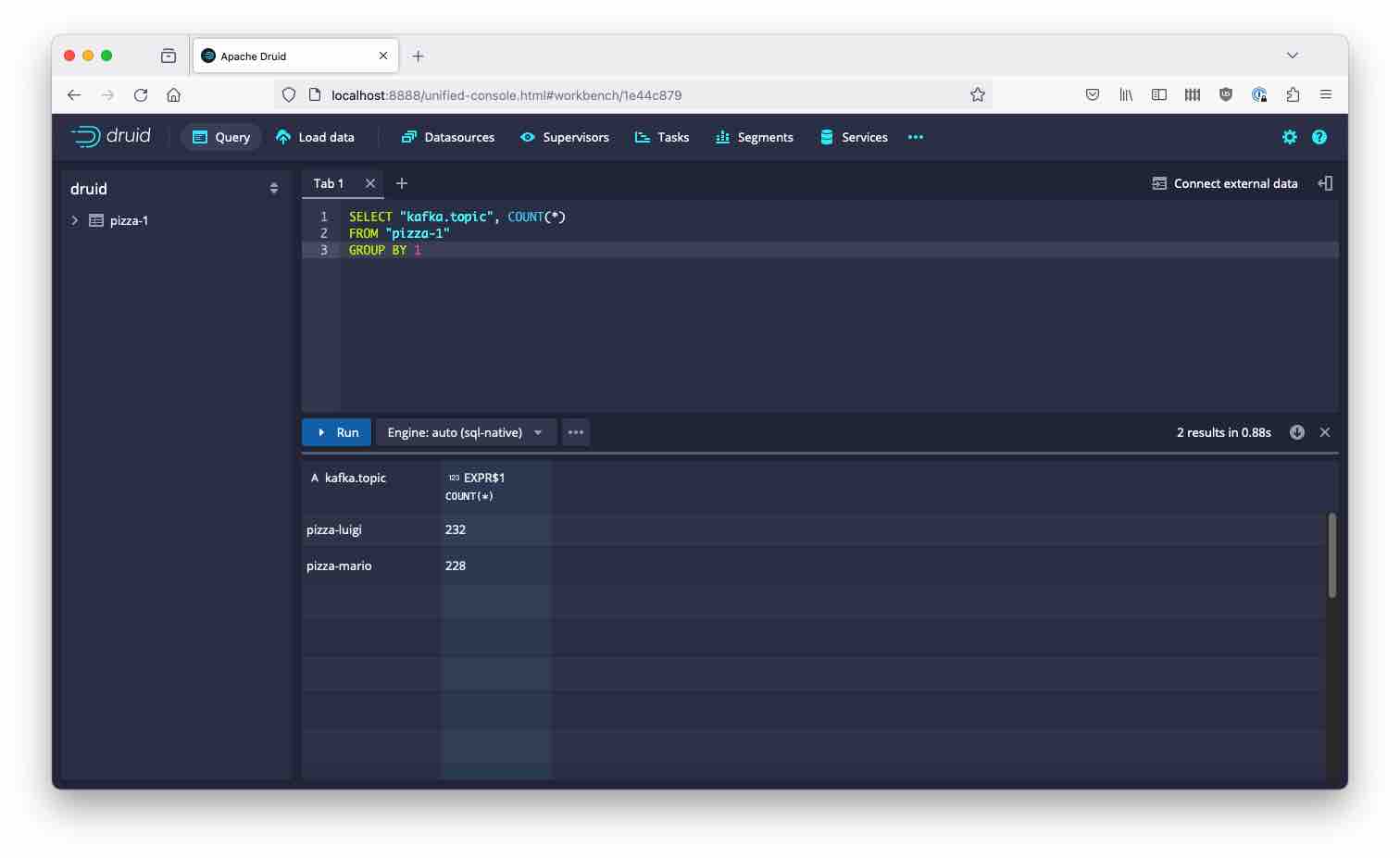
What if you want to pick up all 3 topics? From the above, it should be clear - you need to pad the regular expression with .* on both sides:
You can try it yourself!
Task management
Druid will pick up any topics that match the topicPattern, even if new topics are added during the ingestion.
How are partitions assigned to tasks?
The Supervisor will fetch the list of all partitions from all topics and assign the list of these partitions in same way as it assigns the partitions for one topic. In detail this means (quote from the documentation):
When ingesting data from multiple topics, partitions are assigned based on the hashcode of the topic name and the id of the partition within that topic. The partition assignment might not be uniform across all the tasks.
And looking at the code, this boils down to
Math.abs(31 * topic().hashCode() + partitionId) % taskCount
This heuristic should give a fairly uniform load, provided that the data volumes per partition are comparable.
Conclusion
- You can use
topicPatterninstead oftopicin a Kafka Supervisor spec, to enable ingesting from multiple topics. topicPatternis a regex but the regex has to match the whole topic name- You can have as many active ingestion tasks as the total partitions of all topics. Partitions are assigned to tasks using a hashing algorithm.
"Pizza" by Katrin Gilger is licensed under CC BY-SA 2.0 ![]()
![]()
![]() .
.