Merging Realtime Segments in Apache Druid
So, you want your realtime analytical queries to be really fast, and that’s why you selected Apache Druid! Today, let’s have a look at another aspect of how Druid achieves its amazing performance.
Data Layout and Druid Performance
Druid’s query performance can be influenced by multiple factors in the data layout:
- Segment size. The optimum size of a data segment is about 500 MB. If segments are much bigger than that, those segments need more resources for querying and also parallelism suffers. More often you encounter the opposite problem: there are too many small segments, which slows down query performance.
- Partitioning and sorting of data. Partitioning gives an extra performance boost when you can partition the segments according to the expected query pattern; also, inside a segment data is sorted by time, but then by partitioning key; this further speeds up segment scans by increasing compression ratio. For this to work you need to enable range partitioning.
- Rollup. This reduces both storage and query needs by pre-aggregating data. Ideally you want to have perfect rollup so that each unique combination of dimension values corresponds to exactly one aggregate row. For this to work, again one has to use range or hash partitioning. In fact, with range or hash partitioning only, rollup is always perfect; with dynamic partitioning, rollup is best effort - the resulting table may be multiple times bigger than the optimum.
Let’s find out how Druid optimizes these factors for streaming data - without any external processes!
The Problem with Streaming Data
In batch processing, all the above factors can be addressed easily. Streaming data, however, usually does not come in neatly ordered. The point in streaming ingestion is to have these data available for analytics within a split second after an event occurs: and so, segments are built up in memory and persisted frequently. As a result, after a hand-off (the process of persisting a segment to deep storage) by streaming ingestion, segments are not optimal:
- Segments will usually be fragmented and smaller than optimum because we cannot wait long to initiate a handoff. in addition, we may have to juggle multiple time chunks simultaneously because of late arriving data
- Range partitioning requires multiple steps of mapping and shuffling and merging. This is not possible to do during streaming ingestion so the only allowed partitioning scheme is Dynamic.
- Because data can always be added incrementally, rollup is best effort.
Managing the Lifecycle
This is where many databases would add an external maintenance process that reorganizes data. It is the beauty of Druid that it handles this reorganization largely automatically by a process called autocompaction. Here are a few notes in passing about autocompaction and its capabilities.
I discussed autocompaction briefly in my blog about data lifecycle management in Druid. It is a data compaction process that:
- is done automatically by the Coordinator in the background
- has a simple configuration, either through the Druid API or through the Unified Console GUI
- it is basically a reindexing job - it takes all the segments for a given time chunk and re-ingests them into the same datasource, creating a new version.
Autocompaction can:
- make sure segments have a size close to the target value;
- set/modify the partitioning scheme;
- modify rollup settings;
- modify segment granularity;
- modify query granularity.
It also has a setting to leave the newest data alone so as not to interfere with the ongoing ingestion.
Set partitioning scheme
Because streaming ingestion always produces dynamic partitions, you have to use autocompaction to organize your data in a better scheme. While either hash or range partitioning both achieve perfect rollup, range partitioning is recommended for most cases - particularly if you know typical query patterns in advance.
Modify rollup settings
You can go from a detail to a rollup table using autocompaction. There are some caveats though: this approach makes sense mostly if you are using the same aggregation functions in your queries and in rollup.
Modify segment granularity
Segment granularity defines the time period for each time chunk. If your data volume is low enough to have only segment per time chunk, you might consider increasing segment granularity: if there is only one segment per time chunk, secondary partitioning will do essentially nothing, so you need to make the time chunks bigger in order to to force secondary partitioning into effect.
Make sure segment granularities roll up into each other neatly (for instance, don’t do week to month), or else you are in for some surprises.
Modify query granularity
Query granularity defines the aggregation level inside a segment. The primary timestamp will be truncated to the precision defined by the query granularity, and data is aggregated at that level.
You can define additional aggregation during autocompaction by making the query granularity coarser. This is a data lifecycle operation and some organizations use it to retain detail data up to a certain period, and aggregates for older data. When configuring a segment merge autocompaction, you would not usually do this.
Configure grace period for recent data
Druid will soon have the ability to run ingestion and autocompaction over the same time chunk simultaneously. For now, there’s a setting skipOffsetFromLatest, which is by default set to P1D (one day). Its effect is that data younger than that period are left alone by autocompaction, because we anticipate more data to be ingested for that period. Increase this setting if you expect a lot of late arriving data.
This is an ISO 8601 time period.
Configuring it in the wizard
Autocompaction can be configured using the unified console wizard or the API.
In the console, autocompaction settings can be accessed from the Datasources tab. Clicking the compaction settings for a datasource opens a dialog for the basic settings like partitioning and recent data grace period:
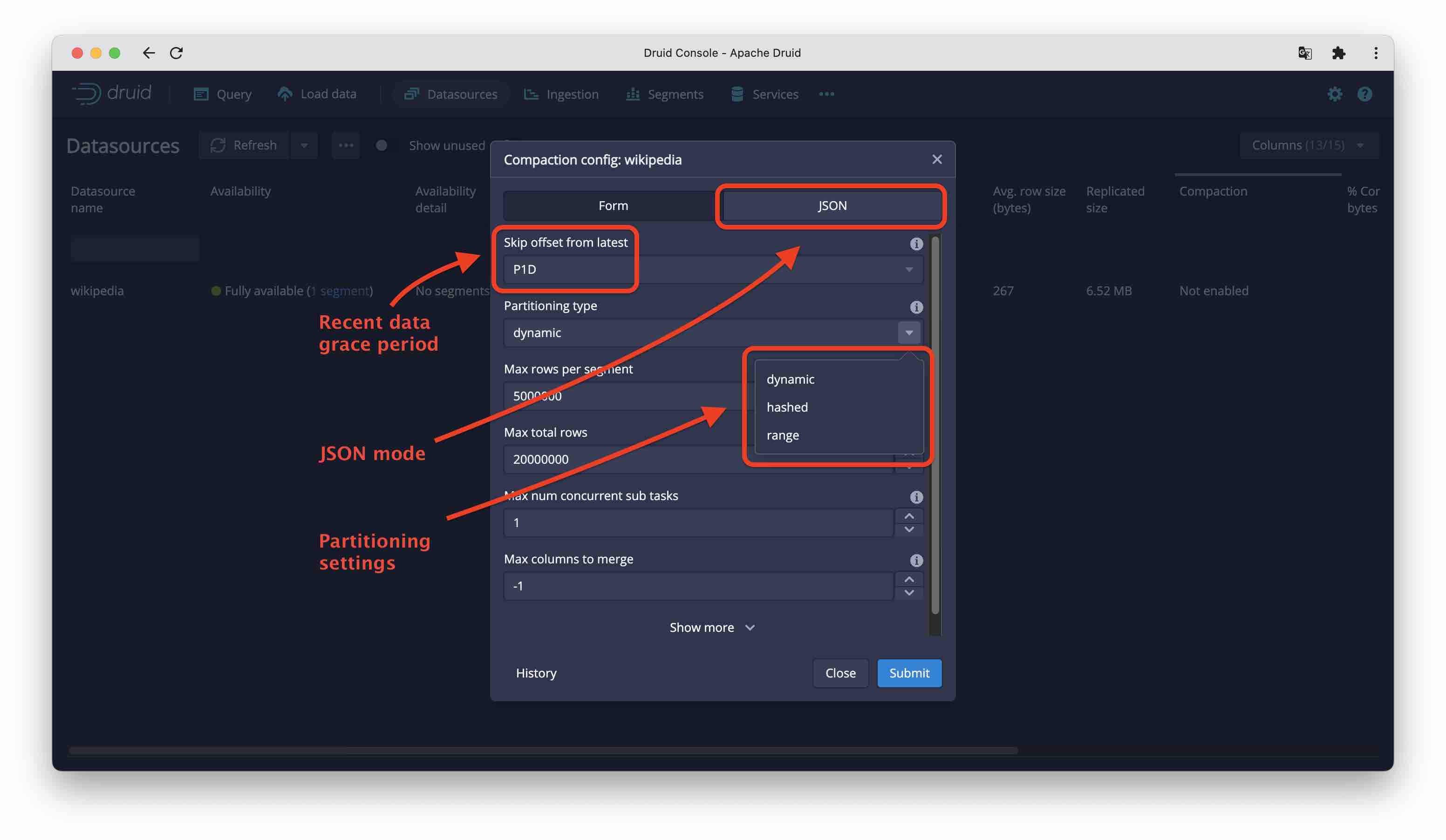
For configuring rollup and granularity settings, you have to enter JSON mode and follow the reference in the documentation.
Outlook
Autocompaction has been with Druid since version 0.13, but it has seen a lot of improvement recently. Some notable changes that will (likely) be released in the near future:
- The algorithm that selects segments for compaction is being tuned to grab segments faster and to use free system resources more efficiently, resulting in a considerable speedup.
- Fully concurrent ingestion and autocompaction - so data layout will be optimized on the fly!
- A lot more options are available to fine tune autocompaction: refer to the documentation for more detail!
Conclusion
This article gave only a glimpse into the capabilities of Druid autocompaction. What we learned:
- Autocompaction is a process that merges and optimizes (among others) realtime ingested segments.
- Autocompaction runs automatically in the background. It requires no extra program invocation or scheduler setup.
- In addition to merging segments, autocompaction can also perform more advanced data lifecycle management tasks with minimal configuration.