Druid 26 Sneak Peek: Window Functions

Great changes have been announced for the upcoming Druid 26.0 release. The one that excites me the most is the introduction of window functions.
Window functions allow a query to interrelate and aggregate rows beyond a simple GROUP BY. Previously, I have looked at ways to emulate such processing patterns using self joins or grouping sets in Druid. But now, we are close to getting window functions as first class citizens.
This is a sneak peek into Druid 26 functionality. In order to use the new functions, you can (as of the time of writing) build Druid from the HEAD of the master branch:
git clone https://github.com/apache/druid.git
cd druid
mvn clean install -Pdist -DskipTests
Then follow the instructions to locate and install the tarball.
All this is still under development so it is undocumented, and hidden behind a secret query context option. (We will look at that in a moment). Also notice, that window functions only work within GROUP BY queries, and there are still some other limitations. But it is fast progressing work.
In this tutorial, you will
- ingest a data sample and
- do a quick cumulative report using window functions.
Disclaimer: This tutorial uses undocumented functionality and unreleased code. This blog is neither endorsed by Imply nor by the Apache Druid PMC. It merely collects the results of personal experiments. The features described here might, in the final release, work differently, or not at all. In addition, the entire build, or execution, may fail. Your mileage may vary.
Let’s do it in practice
I am taking a data sample from the Tinybird blog which is simulated data from an ecommerce store. The data is downloadable from here and has a straightforward format:
- a timestamp
- string fields for product id, user id, and event type
- an extra data field: this is a variable JSON object whose schema depends on the event type.
Let’s see if we can do some interesting things with this!
Ingestion
Ingest the data using SQL based ingestion. In order to keep the extra_data column as nested JSON, apply the PARSE_JSON function in the ingestion query:
REPLACE INTO "events" OVERWRITE ALL
WITH "ext" AS (SELECT *
FROM TABLE(
EXTERN(
'{"type":"http","uris":["https://storage.googleapis.com/tinybird-assets/datasets/guides/events_10K.csv"]}',
'{"type":"csv","findColumnsFromHeader":false,"columns":["date","product_id","user_id","event","extra_data"]}',
'[{"name":"date","type":"string"},{"name":"product_id","type":"string"},{"name":"user_id","type":"long"},{"name":"event","type":"string"},{"name":"extra_data","type":"string"}]'
)
))
SELECT
TIME_PARSE("date") AS "__time",
"product_id",
"user_id",
"event",
PARSE_JSON("extra_data") AS "extra_data"
FROM "ext"
PARTITIONED BY MONTH
You can run this in the query tab of the Druid console like so:
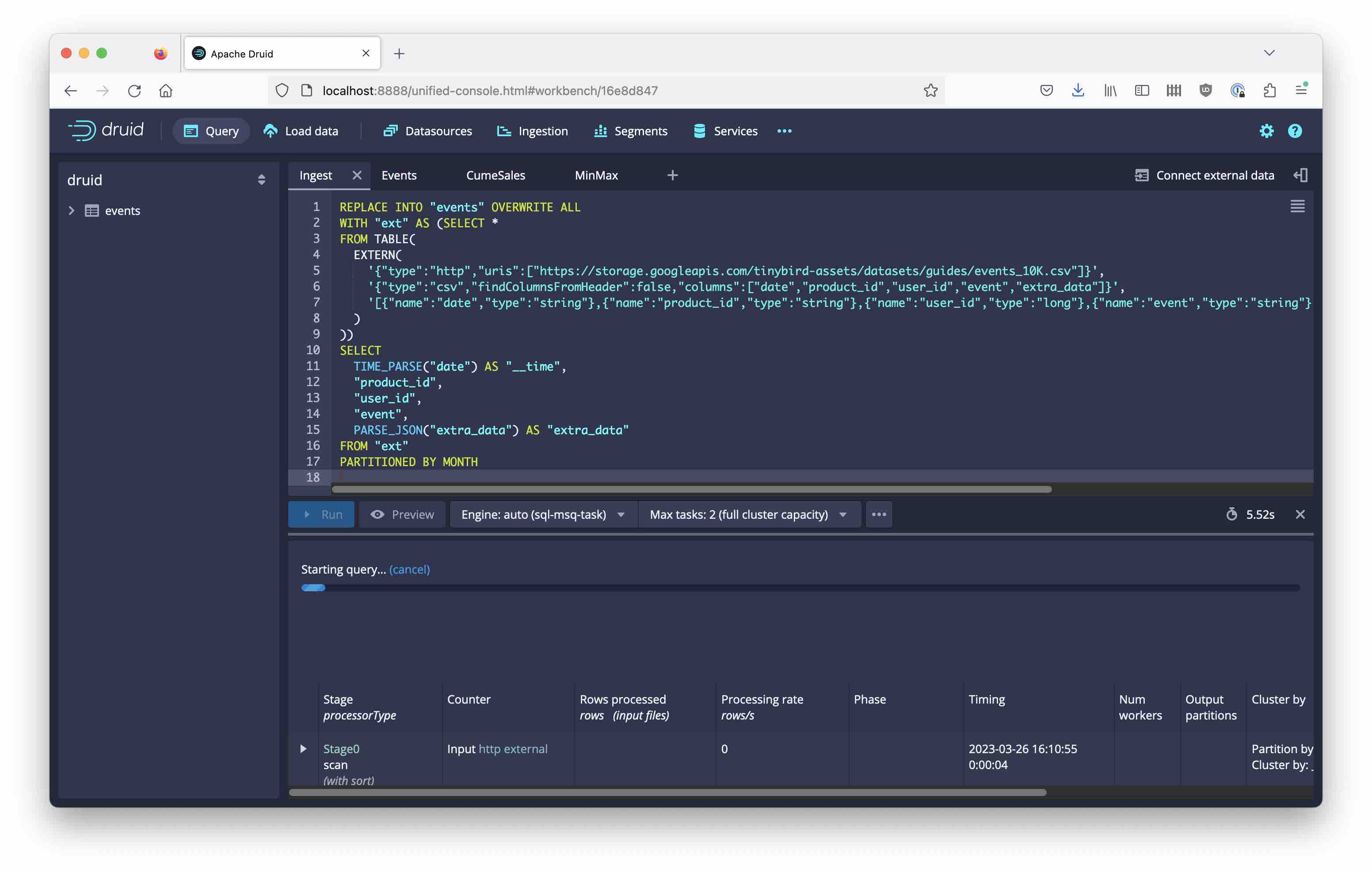
or you can enter the same SQL in the SQL ingestion wizard and monitor progress in the ingestion tab.
Looking at the data
Let’s get an idea of the amount of data in there. One of the neat things in the Druid console is that it has the queries for these basic aggregations in the context menu for each datasource in the query window:
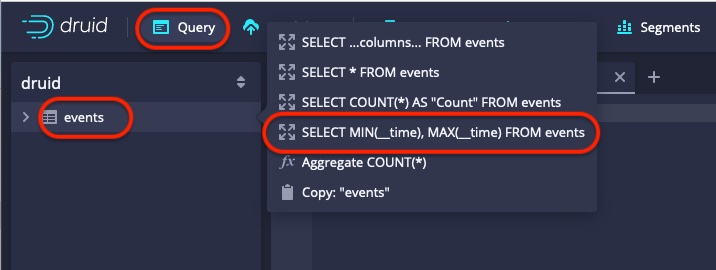
This gives us a quick query for the date range of the sample
SELECT
MIN("__time") AS "min_time",
MAX("__time") AS "max_time"
FROM "events"
GROUP BY ()
which shows that the data is from more than 3 years (2017-2020).
This is why I chose monthly time partitions - given the small size of the sample, yearly would also work well.
Look at the data with a SELECT * FROM "events" query:
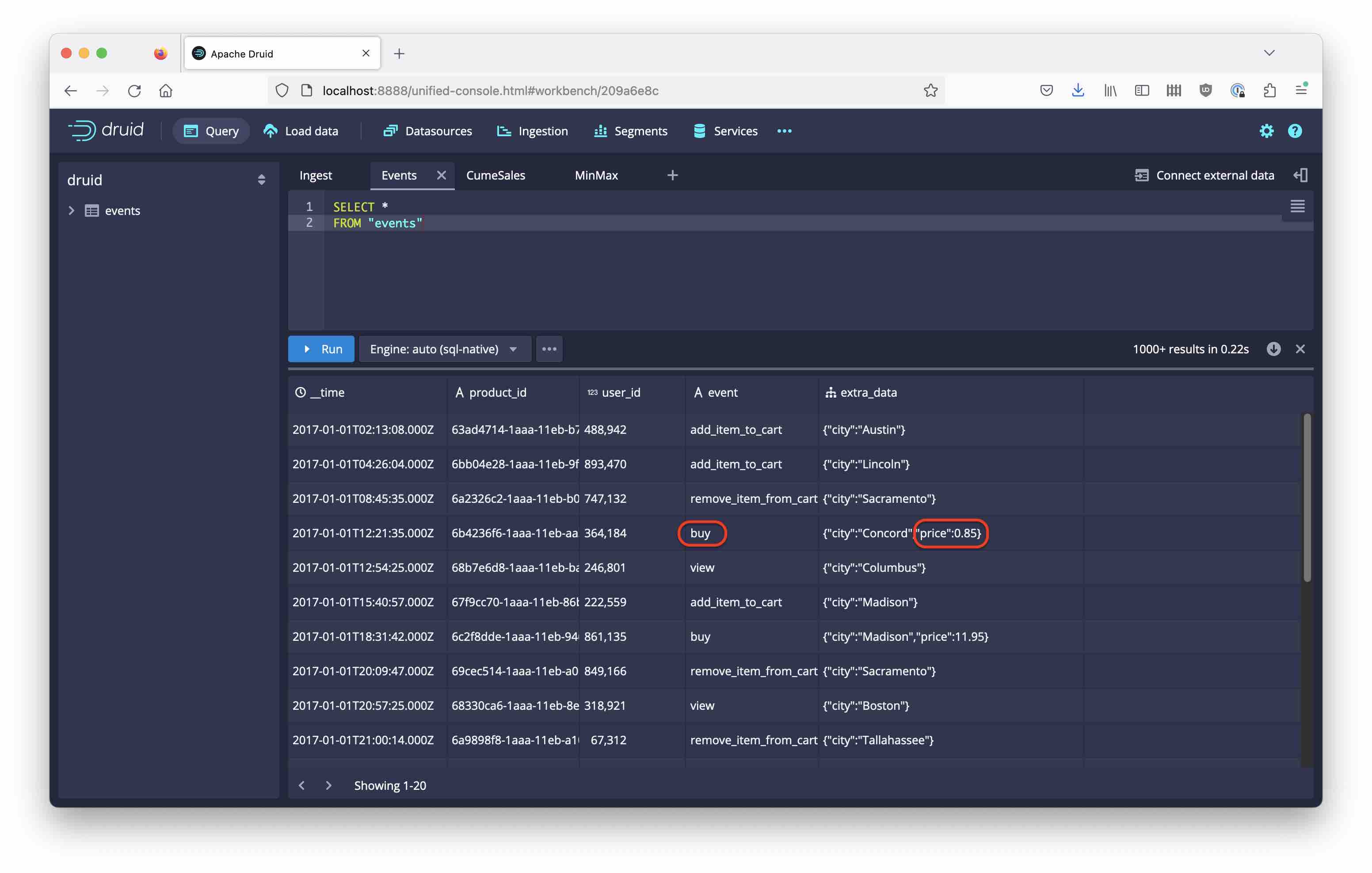
We are interested in buy events: for these, the amount of the purchase is in the price subfield that we can extract with JSON_VALUE. One of the latest additions in Druid is that you can specify the expected return type inside the function call like so:
JSON_VALUE(extra_data, '$.price' RETURNING DOUBLE)
Thus we guarantee that we get only DOUBLE values.
Building the report
I would like to get a report like this: For each day, give me
- the number of purchase transactions for that day
- the cumulative number of transactions from all history up to and including that day
- the total revenue of that day
- the total revenue up to and including that day.
Using a CTE to prepare the fields
In order to prepare that report, let’s first collect the fields we need in a common table expression (CTE):
SELECT
FLOOR(__time TO DAY) AS "date",
COUNT(*) AS purchases,
SUM(JSON_VALUE(extra_data, '$.price' RETURNING DOUBLE)) AS revenue
FROM "events"
WHERE event = 'buy'
GROUP BY 1
Here, we filter the data, extract the price field, and group everything by day. We will package that into a WITH clause that defines the input for the main query.
Setting the context flag to enable experimental window functions
From the menu next to the Run button, select Edit Context
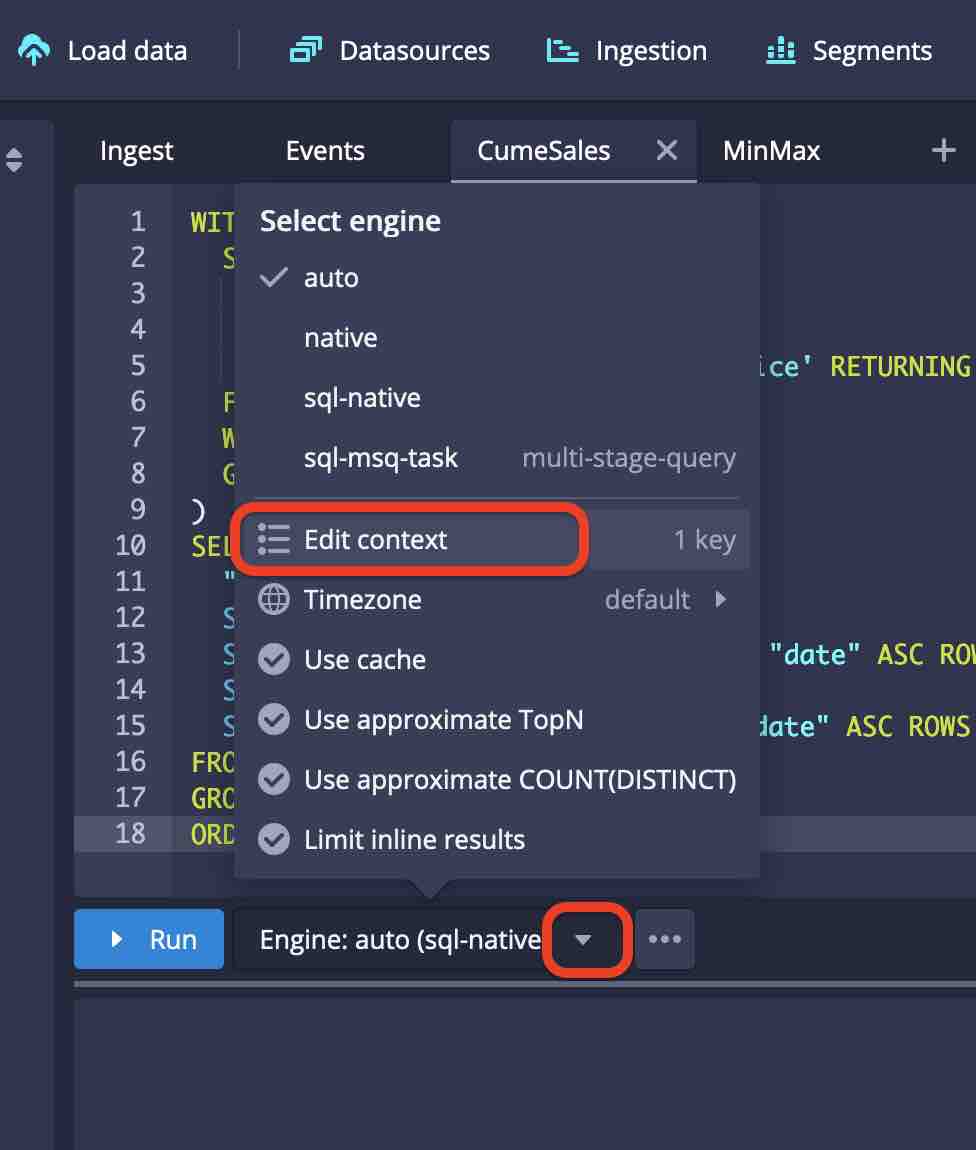
and enter the option "windowsAreForClosers": true to enable window functions:
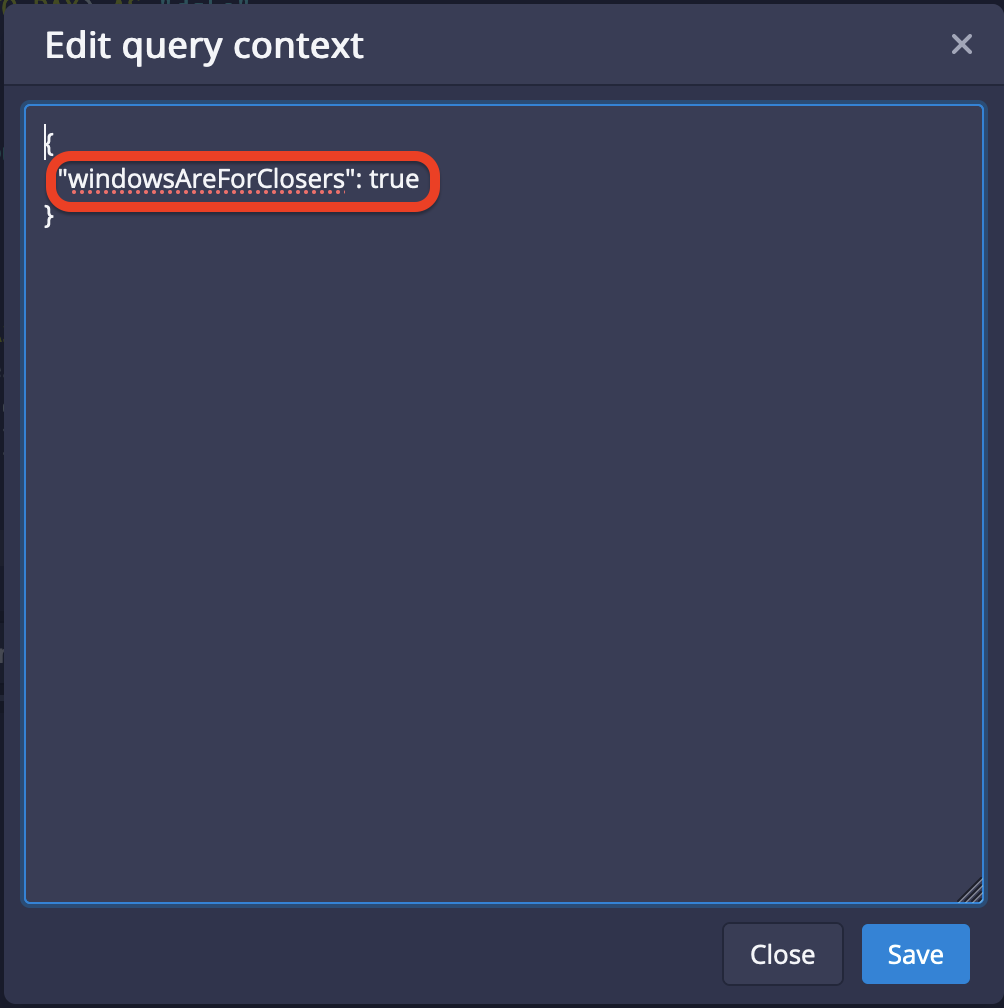
You could also specify the context when running the query through the REST API endpoint (unfortunately not yet through JDBC, though.)
Putting the query together
Now we have everything we need. The cumulative sums will be computed using a window clause like this:
SUM(purchases) OVER (ORDER BY "date" ASC ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW)
where the daily sums have been computed by the GROUP BY in the CTE, and the window aggregation does the cumulative sums.
Here is the whole query:
WITH cte AS (
SELECT
FLOOR(__time TO DAY) AS "date",
COUNT(*) AS purchases,
SUM(JSON_VALUE(extra_data, '$.price' RETURNING DOUBLE)) AS revenue
FROM "events"
WHERE event = 'buy'
GROUP BY 1
)
SELECT
"date",
purchases AS daily_purchases,
SUM(purchases) OVER (ORDER BY "date" ASC ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW) AS cume_purchases,
revenue AS daily_revenue,
SUM(revenue) OVER (ORDER BY "date" ASC ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW) AS cume_revenue
FROM cte
ORDER BY 1 ASC
You can run it in the console:
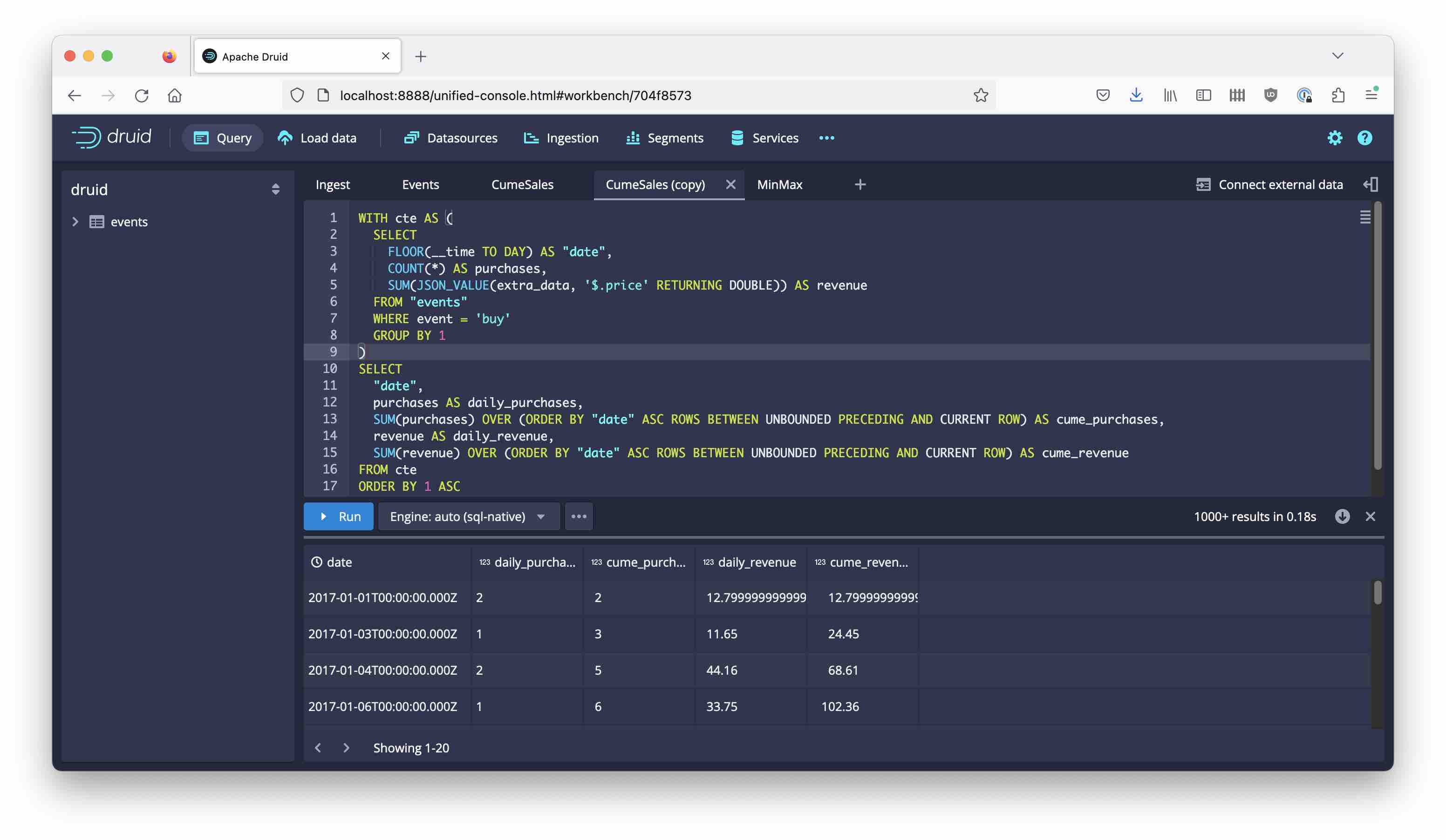
The columns named cume… contain the result of the window aggregations.
And using the Explain function, notice that this SQL actually translates to a new native query type:
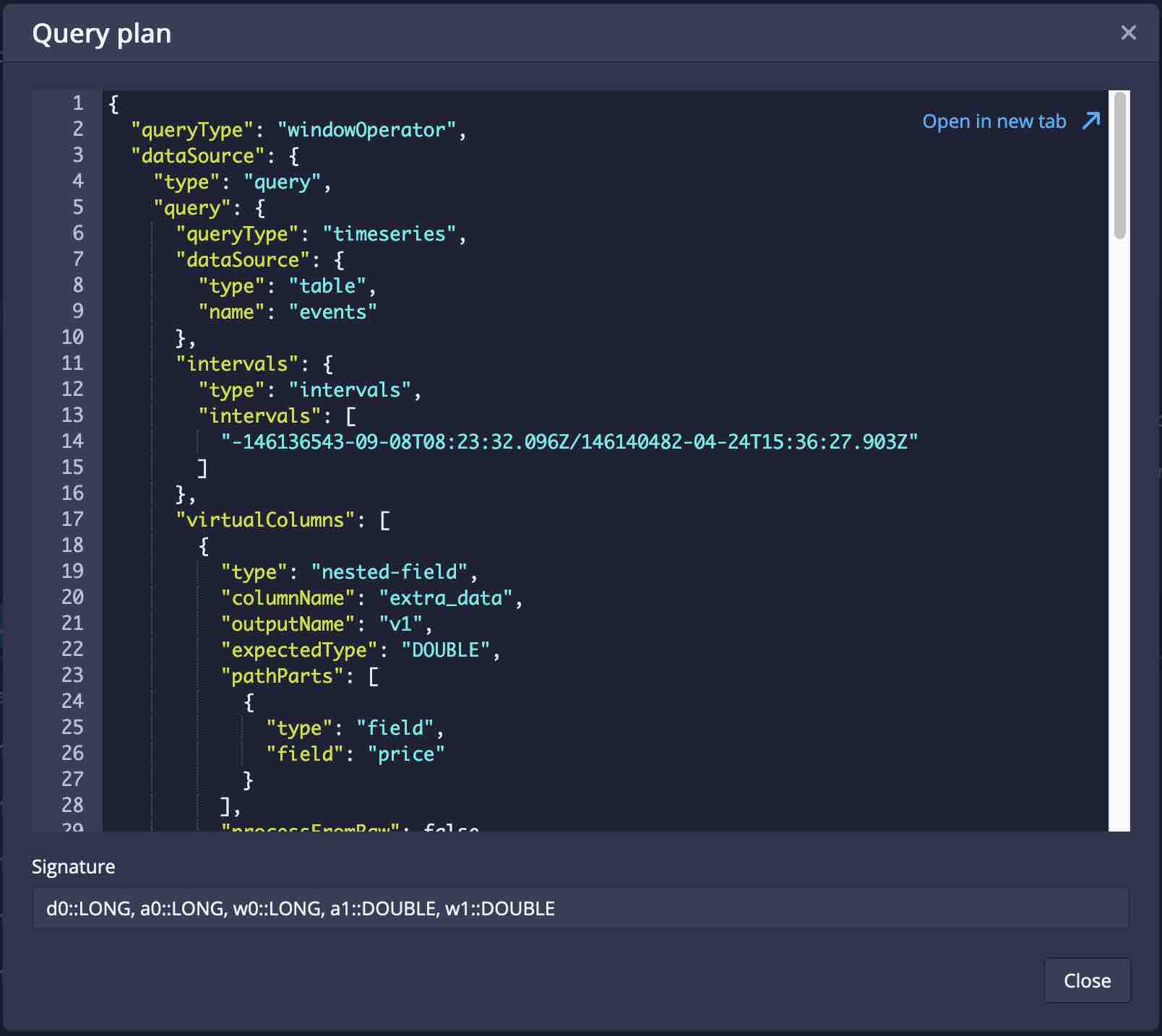
Conclusion
- If you take a sneak peek at the public Druid repository, you can follow the work that is being done on window functions. While these are currently a bit rough around the edges, you can already do quite a bit with this new functionality.
- Because it is work in progress, this is currently undocumented and hidden behind a feature flag that needs to be enabled in the query context for each query that uses it.
- This is evolving rapidly and will likely see a lot of enhancements very soon.
Edit 2023-03-27: One of my readers pointed out a simplification of the query - the first version carried a redundant GROUP BY in the final query, but it turns out that Druid is smart enough to plan a grouped (timeseries) query based on the grouping in the CTE. This is reflected above now.
“This image is taken from Page 500 of Praktisches Kochbuch für die gewöhnliche und feinere Küche” by Medical Heritage Library, Inc. is licensed under CC BY-NC-SA 2.0 ![]()
![]()
![]()
![]() .
.