Selective Bulk Upserts in Apache Druid
Apache Druid is designed for high query speed. The data segments that make up a Druid datasource (think: table) are generally immutable: You do not update or replace individual rows of data; however you can replace an entire segment with a new version of itself.
Sometimes in analytics, you have to update or insert rows of data in a segment. This may be due to a state change - such as an order being shipped, or canceled, or returned. Generally, you would have a key column in your data, and based on that key you would update a row if it exists in the table already, and insert it otherwise. This is called upsert, after the name of the command that is used in many SQL dialects.
This Imply blog talks about the various strategies to handle such scenarios with Druid. But today, I want to look at a special case of Upsert, where you want to update or insert a bunch of rows based on a key and time interval.
The use case
I encountered this scenario with some of my AdTech customers. They obtain performance analytics data by issuing API calls to the ad network providers. These API calls have to cover certain predefined time ranges - data is downloaded in bulk. Moreover, depending on factors like late arriving conversion data or changes of the attribution model, metrics associated with the data rows may change over time.
If we want to make these data available in Druid, we will have to cut out existing data by key and interval, and transplant the new data instead, like in this diagram:
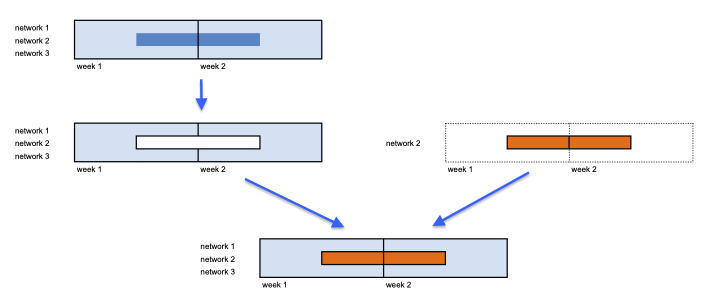
Solution outline
In order to achieve this behavior in Druid, we will use a combining input source in the ingestion spec. A combining input source contains a list of delegate input sources - we will use two, but you can actually have more than two.
The ingestion process will read data from all delegate input sources and ingest them, much like what a union all in SQL does. The nice thing is that this process is transactional - it will succeed either completely, or not at all.
We have to make sure that all input sources have the same schema and, where that applies, the same input format. In practice this means:
- you can combine multiple external sources only if they are all parsed in the same way
- or you can combine external sources like above with any number of
druidinput sources (reindexing).
The latter is what we are going to do.
Tutorial: How to do it in practise
In this tutorial, we will set up a bulk upsert using the combining input source technique and two stripped down sample data sets.
We will:
- load an initial data sample for multiple ad networks
- show the upsert technique by replacing data for one network and a specific date range.
The tutorial can be done using the Druid 25.0 quickstart.
Note: Because the tutorial assumes that you are running all Druid processes on a single machine, it can work with local file system data. In a cluster setup, you would have to use a network mount or (more commonly) cloud storage, like S3.
Initial load
The first data sample serves to populate the table. It has one week’s worth of data from three ad networks:
{"date": "2023-01-01T00:00:00Z", "ad_network": "gaagle", "ads_impressions": 2770, "ads_revenue": 330.69}
{"date": "2023-01-01T00:00:00Z", "ad_network": "fakebook", "ads_impressions": 9646, "ads_revenue": 137.85}
{"date": "2023-01-01T00:00:00Z", "ad_network": "twottr", "ads_impressions": 1139, "ads_revenue": 493.73}
{"date": "2023-01-02T00:00:00Z", "ad_network": "gaagle", "ads_impressions": 9066, "ads_revenue": 368.66}
{"date": "2023-01-02T00:00:00Z", "ad_network": "fakebook", "ads_impressions": 4426, "ads_revenue": 170.96}
{"date": "2023-01-02T00:00:00Z", "ad_network": "twottr", "ads_impressions": 9110, "ads_revenue": 452.2}
{"date": "2023-01-03T00:00:00Z", "ad_network": "gaagle", "ads_impressions": 3275, "ads_revenue": 363.53}
{"date": "2023-01-03T00:00:00Z", "ad_network": "fakebook", "ads_impressions": 9494, "ads_revenue": 426.37}
{"date": "2023-01-03T00:00:00Z", "ad_network": "twottr", "ads_impressions": 4325, "ads_revenue": 107.44}
{"date": "2023-01-04T00:00:00Z", "ad_network": "gaagle", "ads_impressions": 8816, "ads_revenue": 311.53}
{"date": "2023-01-04T00:00:00Z", "ad_network": "fakebook", "ads_impressions": 8955, "ads_revenue": 254.5}
{"date": "2023-01-04T00:00:00Z", "ad_network": "twottr", "ads_impressions": 6905, "ads_revenue": 211.74}
{"date": "2023-01-05T00:00:00Z", "ad_network": "gaagle", "ads_impressions": 3075, "ads_revenue": 382.41}
{"date": "2023-01-05T00:00:00Z", "ad_network": "fakebook", "ads_impressions": 4870, "ads_revenue": 205.84}
{"date": "2023-01-05T00:00:00Z", "ad_network": "twottr", "ads_impressions": 1418, "ads_revenue": 282.21}
{"date": "2023-01-06T00:00:00Z", "ad_network": "gaagle", "ads_impressions": 7413, "ads_revenue": 322.43}
{"date": "2023-01-06T00:00:00Z", "ad_network": "fakebook", "ads_impressions": 1251, "ads_revenue": 265.52}
{"date": "2023-01-06T00:00:00Z", "ad_network": "twottr", "ads_impressions": 8055, "ads_revenue": 394.56}
{"date": "2023-01-07T00:00:00Z", "ad_network": "gaagle", "ads_impressions": 4279, "ads_revenue": 317.84}
{"date": "2023-01-07T00:00:00Z", "ad_network": "fakebook", "ads_impressions": 5848, "ads_revenue": 162.96}
{"date": "2023-01-07T00:00:00Z", "ad_network": "twottr", "ads_impressions": 9449, "ads_revenue": 379.21}
Save this sample locally to a file named data1.json and ingest it using this ingestion spec (replace the path in baseDir with the path you saved the sample file to):
{
"type": "index_parallel",
"spec": {
"ioConfig": {
"type": "index_parallel",
"inputSource": {
"type": "local",
"baseDir": "/<my base path>",
"filter": "data1.json"
},
"inputFormat": {
"type": "json"
},
"appendToExisting": false
},
"tuningConfig": {
"type": "index_parallel",
"partitionsSpec": {
"type": "hashed"
},
"forceGuaranteedRollup": true
},
"dataSchema": {
"dataSource": "ad_data",
"timestampSpec": {
"column": "date",
"format": "iso"
},
"dimensionsSpec": {
"dimensions": [
"ad_network",
{
"type": "long",
"name": "ads_impressions"
},
{
"name": "ads_revenue",
"type": "double"
}
]
},
"granularitySpec": {
"queryGranularity": "none",
"rollup": false,
"segmentGranularity": "week"
}
}
}
}
You can create this ingestion spec by clicking through the console wizard, too. There are a few notable settings here though:
- I’ve used hash partitioning over all partitions here. The default in the wizard is dynamic partitioning, but you would usually use dymanic partitioning with batch data only if you want to append data to an existing data set. In all other cases, use hash or range partitioning.
- I’ve configured weekly segments. This is to show that the technique works even if the updated range does not align with segment boundaries.
Doing the upsert
Now, let’s fast-forward two days in time. We have downloaded a bunch of new and updated data from the gaagle network. The new data looks like this:
{"date": "2023-01-03T00:00:00Z", "ad_network": "gaagle", "ads_impressions": 4521, "ads_revenue": 378.65}
{"date": "2023-01-04T00:00:00Z", "ad_network": "gaagle", "ads_impressions": 4330, "ads_revenue": 464.02}
{"date": "2023-01-05T00:00:00Z", "ad_network": "gaagle", "ads_impressions": 6088, "ads_revenue": 320.57}
{"date": "2023-01-06T00:00:00Z", "ad_network": "gaagle", "ads_impressions": 3417, "ads_revenue": 162.77}
{"date": "2023-01-07T00:00:00Z", "ad_network": "gaagle", "ads_impressions": 9762, "ads_revenue": 76.27}
{"date": "2023-01-08T00:00:00Z", "ad_network": "gaagle", "ads_impressions": 1484, "ads_revenue": 188.17}
{"date": "2023-01-09T00:00:00Z", "ad_network": "gaagle", "ads_impressions": 1845, "ads_revenue": 287.5}
Save this sample as data2.json and proceed to replace/insert the new data using this spec:
{
"type": "index_parallel",
"spec": {
"ioConfig": {
"type": "index_parallel",
"inputSource": {
"type": "combining",
"delegates": [
{
"type": "druid",
"dataSource": "ad_data",
"interval": "1000/3000",
"filter": {
"type": "not",
"field": {
"type": "and",
"fields": [
{
"type": "selector",
"dimension": "ad_network",
"value": "gaagle"
},
{
"type": "interval",
"dimension": "__time",
"intervals": [
"2023-01-03T00:00:00Z/2023-01-10T00:00:00Z"
],
"extractionFn": null
}
]
}
}
},
{
"type": "local",
"files": ["/<my base path>/data2.json"]
}
]
},
"inputFormat": {
"type": "json"
}
},
"tuningConfig": {
"type": "index_parallel",
"partitionsSpec": {
"type": "hashed"
},
"forceGuaranteedRollup": true,
"maxNumConcurrentSubTasks": 2
},
"dataSchema": {
"timestampSpec": {
"column": "__time",
"missingValue": "2010-01-01T00:00:00Z"
},
"transformSpec": {
"transforms": [
{
"name": "__time",
"type": "expression",
"expression": "nvl(timestamp_parse(date), \"__time\")"
}
]
},
"granularitySpec": {
"rollup": false,
"queryGranularity": "none",
"segmentGranularity": "week"
},
"dimensionsSpec": {
"dimensions": [
{
"name": "ad_network",
"type": "string"
},
{
"name": "ads_impressions",
"type": "long"
},
{
"name": "ads_revenue",
"type": "double"
}
]
},
"dataSource": "ad_data"
}
}
}
Here’s the result of a SELECT * query after the ingestion finishes:
| __time | ad_network | ads_impressions | ads_revenue |
|---|---|---|---|
| 2023-01-01T00:00:00.000Z | fakebook | 9646 | 137.85 |
| 2023-01-01T00:00:00.000Z | gaagle | 2770 | 330.69 |
| 2023-01-01T00:00:00.000Z | twottr | 1139 | 493.73 |
| 2023-01-02T00:00:00.000Z | fakebook | 4426 | 170.96 |
| 2023-01-02T00:00:00.000Z | gaagle | 9066 | 368.66 |
| 2023-01-02T00:00:00.000Z | twottr | 9110 | 452.2 |
| 2023-01-03T00:00:00.000Z | fakebook | 9494 | 426.37 |
| 2023-01-03T00:00:00.000Z | gaagle | 4521 | 378.65 |
| 2023-01-03T00:00:00.000Z | twottr | 4325 | 107.44 |
| 2023-01-04T00:00:00.000Z | fakebook | 8955 | 254.5 |
| 2023-01-04T00:00:00.000Z | gaagle | 4330 | 464.02 |
| 2023-01-04T00:00:00.000Z | twottr | 6905 | 211.74 |
| 2023-01-05T00:00:00.000Z | fakebook | 4870 | 205.84 |
| 2023-01-05T00:00:00.000Z | gaagle | 6088 | 320.57 |
| 2023-01-05T00:00:00.000Z | twottr | 1418 | 282.21 |
| 2023-01-06T00:00:00.000Z | fakebook | 1251 | 265.52 |
| 2023-01-06T00:00:00.000Z | gaagle | 3417 | 162.77 |
| 2023-01-06T00:00:00.000Z | twottr | 8055 | 394.56 |
| 2023-01-07T00:00:00.000Z | fakebook | 5848 | 162.96 |
| 2023-01-07T00:00:00.000Z | gaagle | 9762 | 76.27 |
| 2023-01-07T00:00:00.000Z | twottr | 9449 | 379.21 |
| 2023-01-08T00:00:00.000Z | gaagle | 1484 | 188.17 |
| 2023-01-09T00:00:00.000Z | gaagle | 1845 | 287.5 |
Note how all the rows in italics come from the second data set. They have either been inserted (the last two rows), or they replace previous rows for the same time interval and network.
Taking a closer look
Let’s go through some interesting points in the ingestion spec.
The input sources
As mentioned above, the combining input source works like a union all. The members of the union are specified in the delegates array, and they are input source definitions themselves.
This tutorial uses only two input sources, but generally you could have more than two. A delegate input source can be any input source, but with one important restriction: all input sources that need an inputFormat have to share the same inputFormat.
This means that as soon as file-shaped input sources are involved, the all have to be the same format. But you can freely combine file-shaped input with Druid reindexing, and probably also with SQL input (although I haven’t tested that.)
Here is the combine clause for our tutorial:
"inputSource": {
"type": "combining",
"delegates": [
{
"type": "druid",
"dataSource": "ad_data",
...
},
{
"type": "local",
"files": ["/<my base path>/data2.json"]
}
]
}
The first part pulls data from the existing Druid datasource. It will apply a filter (left out above for brevity), which I am covering in the next paragraph. The second part gets the new data from a file.
The file input source does not have the ability to specify a filter, but then, we don’t need it because the file contains exactly the data we want to ingest.
The schemas of the two sources match almost but not quite. We will come to this when we look at the timestamp definition.
Druid reindexing: Interval boundaries
Any Druid reindexing job needs to define the interval that will be considered as the domain of reindexing. If you want to consider all data that exists in the datasource, specify an interval that is large enough to cover all possible timestamps:
"interval": "1000/3000",
This shorthand is actually a set of two ISO 8601 timestamps with year granularity! The numbers are year numbers, and year numbers alone are perfectly legal timestamps.
Why do we not specify the timestamp filter here? We cannot use the "interval" setting because we want to cut out an interval. I’ll come to this in the next paragraph.
(What we can do with "interval" though, is limit the amount of data that Druid needs to reindex. If you know that all the data you are going to touch is within a specific time range, this can speed up things. But make sure that your interval boundaries are aligned with the segment boundaries in Druid, otherwise you will lose data.)
Ingestion filter on the Druid reindexing part
Here’s where cutting out of data happens. The Druid input source allows you to introduce a set of filters that work the same way as filters inside the transformSpec, but, and this is important, are applied to that input source only.
Filters offer various ways to specify filter conditions, and to string them together using boolean operators in prefix notation. The condition tells us which rows to keep. Here is what the filter for our case looks like:
"filter": {
"type": "not",
"field": {
"type": "and",
"fields": [
{
"type": "selector",
"dimension": "ad_network",
"value": "gaagle"
},
{
"type": "interval",
"dimension": "__time",
"intervals": [
"2023-01-03T00:00:00Z/2023-01-10T00:00:00Z"
],
"extractionFn": null
}
]
}
}
This filter will keep all rows that satisfy a condition of not(and(ad_network=gaagle, timestamp in [interval])). Or, to express it in simpler words, it drops all rows that are from gaagle and within the time interval 3 to 10 January (left inclusive).
Schema alignment: Timestamp definition
Most of the fields in the Druid datasource and in the input file match by name and type, because we defined it that way. There is one notable exception though:
The primary timestamp comes from a column date and is in ISO-8601 format, but in Druid the timestamp is a long value, expressed in milliseconds since Epoch, and is always named __time.
If you do not reconcile these different timestamps, you will get confusing errors. Maybe Druid will not ingest fresh data at all. In another scenario, I saw an error complaining about a missing interval definition in the partition configuration. At any rate, watch out for your timestamps.
Luckily, it is easy to populate the timestamp using a Druid expression. Here’s how it works:
"timestampSpec": {
"column": "__time",
"missingValue": "2010-01-01T00:00:00Z"
},
"transformSpec": {
"transforms": [
{
"name": "__time",
"type": "expression",
"expression": "nvl(timestamp_parse(date), \"__time\")"
}
]
}
- The default is to pick up the timestamp from the
__timecolumn, which works for the reindexing case. This is coded intimestampSpec. - A transform overrides the value, replacing it by what is found in the
datecolumn (the file case.) If that value doesn’t exist, we fall back to__time.
Tuning configuration
The documentation mentions that
The secondary partitioning method determines the requisite number of concurrent worker tasks that run in parallel to complete ingestion with the Combining input source. Set this value in
maxNumConcurrentSubTasksintuningConfigbased on the secondary partitioning method:
rangeorsingle_dimpartitioning: greater than or equal to 1hashedordynamicpartitioning: greater than or equal to 2
This advice is to be taken seriously. If you try to run with an insufficient number of subtasks you will get a highly misleading error message that looks like:
java.lang.UnsupportedOperationException: Implement this method properly if needsFormat() = true
Make sure you configure at least two concurrent subtasks if you are using hashed or dynamic partitioning.
Conclusion
This tutorial showed how to fold new and updated data into an existing datasource, to the effect of a selective bulk upsert. Let’s recap a few learnings:
- Selective bulk upserts are done using the
combining inputSourceidiom in Druid. - For reindexing Druid data, choose the
intervalto align with segment boundaries, or to be large enough to cover all data. You can apply fine grained date/time filters in thefilterclause. - Ingestion filters are very expressive and allow a detailed specification of which data to retain or replace.
- Make sure timestamp definitions are aligned between your Druid datasource and external data.
- Configure a sufficient number of subtasks, according to the documentation.