Druid Data Cookbook: Modeling Flag Lists

In timeseries data, you may have lists of boolean flags that come with each data record. Running a Druid ingestion on that, you would create a large number of dimensions. If you have followed the Druid Data Modeling class, you know that reducing the number of dimensions is one goal of optimizing the data model in Druid.
This is one of the prime use cases for multi-value dimensions.
Rather than having one dimension per flag, create one multi-value dimension for all flags. So {"f1":true, "f2":false, "f3":true, "f10":true} is transformed to {"flags":["f1","f3","f10"]}. You can then
- filter by the presence or absence of individual values,
- count the number of occurrences of each value in a single
GROUP BYclause, - or apply set operations and complex filters with MV functions.
Generating Sample Data
Let’s generate ourselves some fake timeseries data. The data format is simple:
- a timestamp
- a quantity and value, where the quantity is a single random letter
- various boolean flags that may or may not conform to the naming convention “f” plus any number of digits.
Here’s a small python script for generating the data, you will need the Faker module installed:
import json
import time
from faker import Faker
maxRecords = 20000
fake = Faker()
flagsOrNot = [ "f1", "f2", "f3", "f10", "f1f", "ff1", "abc" ];
def main():
ts = time.time() - 10 * 86400 # 10 days back
for id in range(maxRecords):
emitRecord = {
"timestamp" : int(round(ts)),
"quantity" : fake.random_element(elements=('a', 'b', 'c', 'd')),
"value" : fake.random_number(digits=3) / 100.0,
}
emitRecord.update( {
k : fake.boolean() for k in flagsOrNot
} )
print(json.dumps(emitRecord))
ts += fake.random_int(min=1, max=60)
if __name__ == "__main__":
main()
Run the script and save the output in a file named flags.json.
Extracting the flag data with jq
We want to select only those fields from the JSON object that have names that start with “f” and have only digits after that. Let’s break this down into steps.
-
First, I use the
to_entriesfunction to transform the JSON object into an array of objects that have fieldskeyandvalue.So,
{ "a" : "1" }becomes[ { "key" : "a", "value" : "1" } ]. - The first
mapstatement selects only those keys that match the regular expression for the flag name (“f” + any number of digits, but nothing else). - The result is filtered by a
selectstatement that keeps only the entries where thevalueevaluates totrue. - The final
mapstatement keeps only the keys for the matching entries and returns them in an array.
This is the filter phrase as you would use it with jq:
to_entries | map(select(.key | match("^f\\d+$")) | select(.value)) | map(.key)
Approach 1: Preprocessing
One way of ingesting the flags as a multi-value dimension is preprocessing. Let’s just add a flags field to each JSON object:
jq -c '. += { "flags": to_entries | map(select(.key | match("^f\\d+$")) | select(.value)) | map(.key) }' < flags.json
This does the trick and it may be good enough. But let’s look at some more elegant solutions.
Approach 2: Using flattenSpec
Upload the data that you generated into Druid. If you are running the local quickstart, you can just use local file ingestion, otherwise just put it into S3.
In the Parse data step, add a column flattening:
And configure it to use jq and this transformation phrase (note the extra backslashes!):
to_entries | map(select(.key | match("^f\\\\d+$")) | select(.value)) | map(.key)
While the console wizard will escape the double quotes on your behalf, the \d in the regular expression needs an extra level of escaping. That is why there are 4 backslashes now.
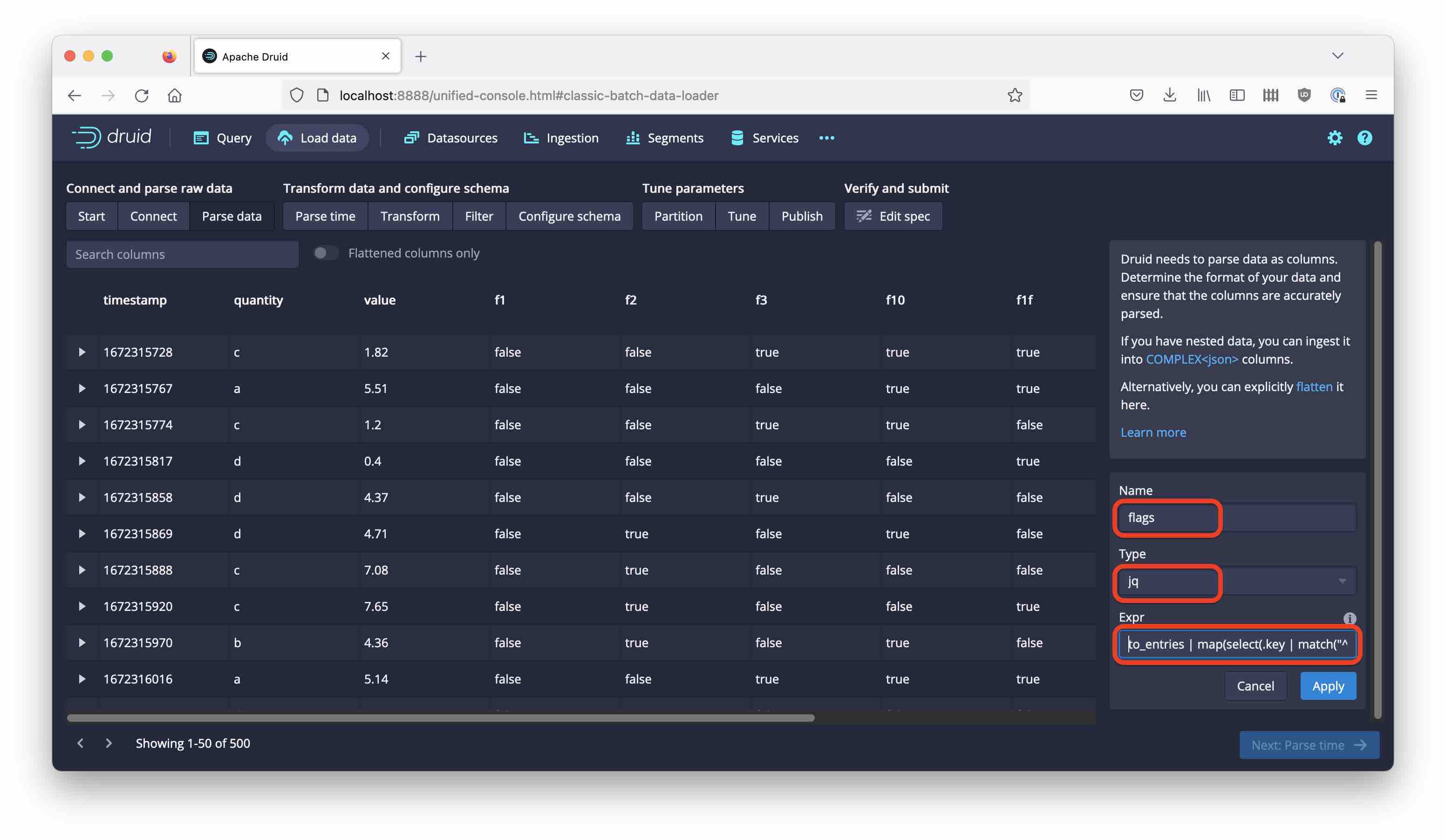
Discard the individual flag columns. Here is the final ingestion spec:
{
"type": "index_parallel",
"spec": {
"ioConfig": {
"type": "index_parallel",
"inputSource": {
"type": "local",
"filter": "flags.json",
"baseDir": "/Users/hellmarbecker/imply-utils/"
},
"inputFormat": {
"type": "json",
"flattenSpec": {
"fields": [
{
"type": "jq",
"name": "flags",
"expr": "to_entries | map(select(.key | match(\"^f\\\\d+$\")) | select(.value)) | map(.key)"
}
]
}
}
},
"tuningConfig": {
"type": "index_parallel",
"partitionsSpec": {
"type": "dynamic"
}
},
"dataSchema": {
"dataSource": "flag_data",
"timestampSpec": {
"column": "timestamp",
"format": "auto"
},
"granularitySpec": {
"queryGranularity": "none",
"rollup": false,
"segmentGranularity": "day"
},
"dimensionsSpec": {
"dimensions": [
{
"name": "flags",
"type": "string",
"multiValueHandling": "SORTED_ARRAY"
},
"quantity",
{
"type": "double",
"name": "value"
}
]
}
}
}
}
Let’s convert this to SQL for MSQ ingestion:
-- This SQL query was auto generated from an ingestion spec
REPLACE INTO "flag_data" OVERWRITE ALL
WITH "source" AS (SELECT * FROM TABLE(
EXTERN(
'{"type":"local","filter":"flags.json","baseDir":"/Users/hellmarbecker/imply-utils/"}',
'{"type":"json","flattenSpec":{"fields":[{"type":"jq","name":"flags","expr":"to_entries | map(select(.key | match(\"^f\\\\d+$\")) | select(.value)) | map(.key)"}]}}',
'[{"name":"timestamp","type":"string"},{"name":"flags","type":"string"},{"name":"quantity","type":"string"},{"name":"value","type":"double"}]'
)
))
SELECT
CASE WHEN CAST("timestamp" AS BIGINT) > 0 THEN MILLIS_TO_TIMESTAMP(CAST("timestamp" AS BIGINT)) ELSE TIME_PARSE("timestamp") END AS __time,
"flags",
"quantity",
"value"
FROM "source"
PARTITIONED BY DAY
As you can see, the inputSource and inputFormat sections from the JSON spec are copied verbatim into the EXTERN clause used by the SQL ingestion.
Conclusion
- When you find a long list of boolean fields (such as flags) in your data, consider modeling them as a multi-value dimension.
- You can apply
jqbased preprocessing in the column flattening spec, which may save you a step of extra processing in your pipeline. - The same trick works with SQL based ingestion, too.
“This image is taken from Page 500 of Praktisches Kochbuch für die gewöhnliche und feinere Küche” by Medical Heritage Library, Inc. is licensed under CC BY-NC-SA 2.0 ![]()
![]()
![]()
![]() .
.