Integrating Apache Druid with Apache Pulsar

With companies adopting the event streaming pattern, analytics has to become more “realtime” too. A great database for event analytics is Apache Druid. Druid connects natively to various event streaming systems such as Kafka and AWS Kinesis.
One of the most advanced modern event streaming platforms is Apache Pulsar. Pulsar has a cloud native architecture that separates the storage layer from the message brokers, claiming unprecendented scalability and flexibility. Sure it would be great to stream events directly from Pulsar into Druid!
The idea has been discussed before by the Imply and StreamNative teams, but up until recently no turnkey solution existed. Pulsar offered a drop-in client library with call compatibility to the Kafka libraries, but using it would usually require rebuilding the entire application, which is not for everyone.
Recently, the folks at StreamNative released Kafka-on-Pulsar (KoP), which is a plugin that makes Pulsar look like a Kafka cluster from an application perspective! Since the compatibility works on the network protocol level, existing clients should continue to work.
If we could set up a Pulsar cluster with KoP enabled, we should be able to leverage the existing Kafka integration in Druid to ingest data directly from Pulsar. Let’s try it out!
We will need to install
- Apache Pulsar and KoP
- Apache Druid
- We also need a data simulator. This will be a simple script that uses the Pulsar commandline client, so we will also see the mapping between Kafka topic names and Pulsar topic names.
I am running all components directly on my laptop.
Installing Pulsar and KoP
Download Pulsar from the Apache Pulsar download website, and untar into your home directory. At the time of this writing, the latest release is 2.10.0.
Download KoP from StreamNative’s GitHub repository. Make sure that the release number of KoP you download matches your Pulsar release. I am using version 2.10.0.2.
Install KoP in apache-pulsar-2.10.0 directory - you need to create a protocols directory and copy the nar file into it:
% cd $HOME/apache-pulsar-2.10.0
% mkdir protocols
% cp ~/Downloads/pulsar-protocol-handler-kafka-2.10.0.2.nar protocols
Configuration for KoP
You have to add a few necessary configuration settings to conf/standalone.conf as per https://github.com/streamnative/kop/blob/master/docs/kop.md:
messagingProtocols=kafka
protocolHandlerDirectory=./protocols
allowAutoTopicCreationType=partitioned # !! overrides the default setting !!
kafkaListeners=PLAINTEXT://127.0.0.1:9092
kafkaAdvertisedListeners=PLAINTEXT://127.0.0.1:9092
brokerEntryMetadataInterceptors=org.apache.pulsar.common.intercept.AppendIndexMetadataInterceptor
brokerDeleteInactiveTopicsEnabled=false # !! overrides the default setting !!
Note that the settings for allowAutoTopicCreationType and brokerDeleteInactiveTopicsEnabled override the default settings, you have to find the lines with the default settings and edit or remove them.
Druid uses Kafka transactions, so we need one more option to make KoP work with Druid:
kafkaTransactionCoordinatorEnabled=true # this is not in the docs but required for Druid
Topic Mapping
While Kafka has a flat namespace, Pulsar has a naming scheme tenant/namespace/topic. You can set the default tenant and namespace for Kafka topics like so: (In conf/standalone.conf)
kafkaTenant=kop
kafkaNamespace=kop
Finally, start Pulsar according to the standalone quickstart instructions:
% bin/pulsar standalone
Installing and Preparing Druid
Download the latest Druid release from the Apache Druid website and untar it into your home directory. We are going to use the Druid quickstart but first we have to solve a little problem.
Port Conflicts
Both Druid and Pulsar use Zookeeper for storing cluster state, and both use the default port 2181. Moreover, Druid’s default configuration exposes the Zookeper command API on port 8080, which is used for admin tasks by Pulsar too.
In a production setup, this would have to be addressed properly. For the purpose of this tutorial, let’s do a simple workaround: We will make Druid use the Zookeeper instance that comes with Pulsar! That means we need to remove Zookeeper from the Druid quickstart.
Make a copy of apache-druid-0.22.1/conf/supervise/single-server/micro-quickstart.conf and remove the Zookeeper line:
!p10 zk bin/run-zk conf
Save this file to apache-druid-0.22.1/conf/supervise/single-server/micro-quickstart-nozk.conf.
Make a copy of bin/start-micro-quickstart and edit the last line to refer to the new configuration file:
exec "$WHEREAMI/supervise" -c "$WHEREAMI/../conf/supervise/single-server/micro-quickstart-nozk.conf"
Save this to bin/start-micro-quickstart-nozk.
We are ready to start Druid:
% bin/start-micro-quickstart-nozk
Generating Data
Let’s push some data into Pulsar. I am going to use the CLI client. Note that the namespace convention we configured will make a topic kop/kop/pulsar-to-druid appear as pulsar-to-druid on the Kafka side. Here’s my pulsar-produce.sh script:
#!/bin/bash
export PULSAR_HOME=$HOME/apache-pulsar-2.10.0
export TOPIC=pulsar-to-druid
while true; do
${PULSAR_HOME}/bin/pulsar-client produce kop/kop/pulsar-to-druid -s "\000" \
-m "{ \"timestamp\": \"$(date -Iseconds)\", \"dim\": \"dim$((1 + RANDOM % 5))\", \"value\": \"$((1 + RANDOM % 100))\" }"
sleep 1
done
This creates a simulated timeseries of JSON messages with messages once a second. The -s option sets the message separator. The default is , which is not good for JSON.
Let’s test this with a Kafka client:
% kcat -b 127.0.0.1:9092 -t pulsar-to-druid -C
{ "timestamp": "2022-04-25T15:04:11+02:00", "dim": "dim5", "value": "5" }
{ "timestamp": "2022-04-25T15:04:16+02:00", "dim": "dim4", "value": "30" }
{ "timestamp": "2022-04-25T15:04:21+02:00", "dim": "dim3", "value": "84" }
{ "timestamp": "2022-04-25T15:04:26+02:00", "dim": "dim1", "value": "33" }
{ "timestamp": "2022-04-25T15:04:30+02:00", "dim": "dim3", "value": "92" }
{ "timestamp": "2022-04-25T15:04:35+02:00", "dim": "dim3", "value": "49" }
{ "timestamp": "2022-04-25T15:04:40+02:00", "dim": "dim3", "value": "40" }
{ "timestamp": "2022-04-25T15:04:45+02:00", "dim": "dim2", "value": "81" }
This works fine. (Side note: kcat needs Kafka transactions enabled, too!)
Ingesting Pulsar Data into Druid
Let’s try if we can connect to Pulsar from the Druid console! Start a new ingestion, choose Kafka and enter the connection detail just like you would for Kafka:
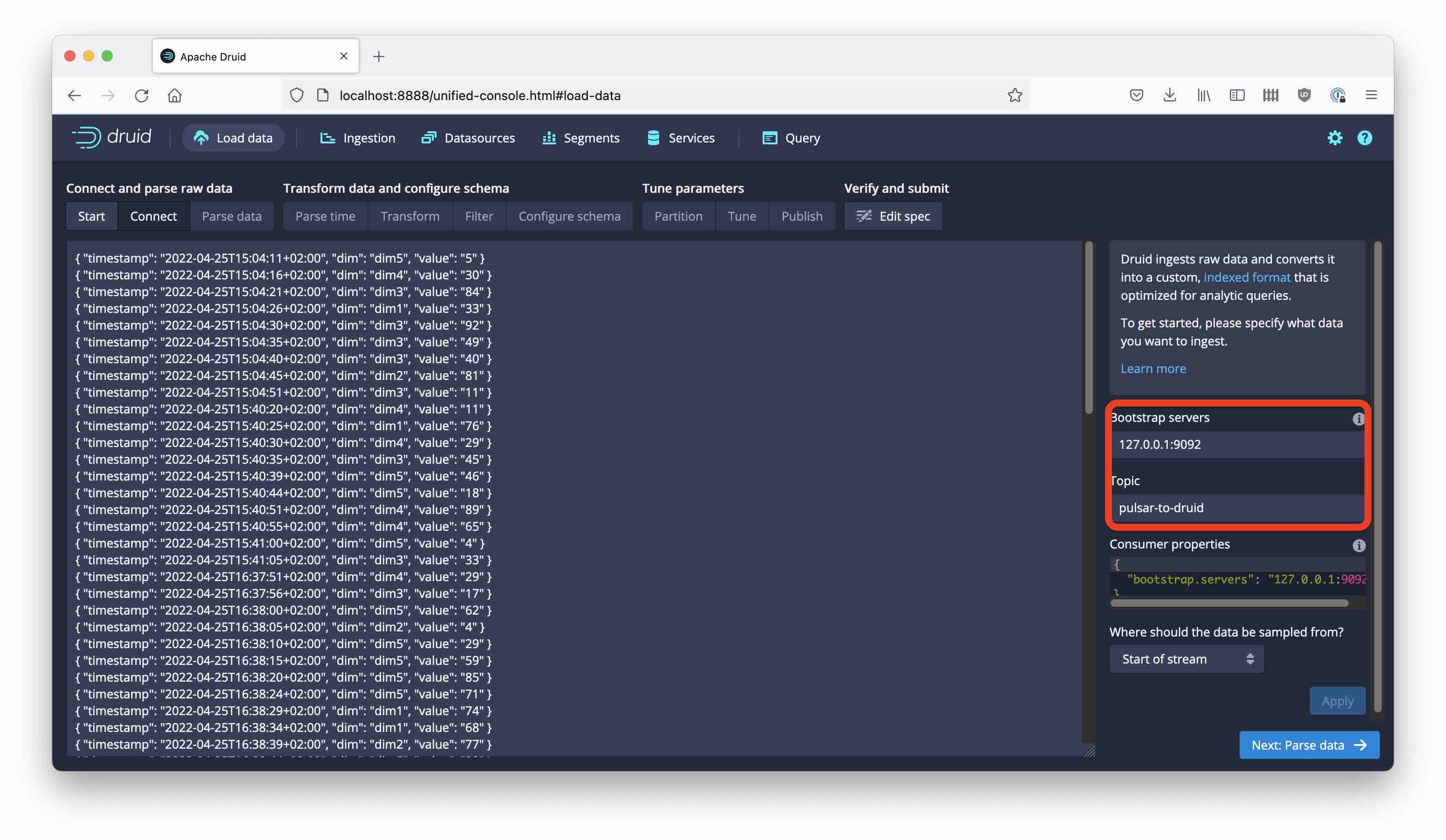
And from here it’s just standard steps to ingest data!
Learnings
- With StreamNative’s KoP, all existing software can talk to Pulsar instead of Kafka.
- Druid integration with KoP is a breeze.
- Spend some time on the namespace mapping between Kafka emulation and Pulsar.
- The
kafkaTransactionCoordinatorEnabledis crucial to make Druid work with KoP.