Apache Druid in AdTech: Computing eCPM values for rolled-up data
Here’s an interesting use case that was inspired by a question in the Druid Community Forum.
Background
AdTech companies use various success metrics for their campaigns. One of these is the cost per mille (CPM), which is how much you pay to bring your ad in front of so many eyeballs. German speaking readers may know this metric under the name of Tausenderkontaktpreis (TKP).
Totalling over a campaign, which may involve various creatives, ad networks, and so on, you want to compute the effective cost per mille (eCPM). This is basically a weighted average which would be computed like so:
eCPM = (Total ad spend / Total measured ad impressions) x 1,000
or, based on the individual CPM values that you know:
eCPM = sum(CPM * ad impressions) / sum(ad impressions).
Data Model in Druid
Let’s take a data sample like this:
date|ad_network_id|ads_impressions|ads_revenue|ecpm
2021-12-20|10|2343|543.15|5.4
2021-12-20|10|3453|343.12|3.1
2021-12-20|10|12543|353.9|8.1
Quite straightforward so far: we are going to have date and ad_network_id as dimensions, and the rest are going to be metrics somehow.
In a real life scenario we don’t have three, but several thousand of lines per combination of date and ad_network_id, so we would very much like to activate rollup. But how? The standard aggregations (count, sum, min, max) don’t really help us here. There are some other aggregators, notably avg, that look like we would use them here but they are not allowed during ingestion. And for good reasons: If you compute an average during a rollup ingestion, and then take the average of that in a group by query, you are most certainly doing the Wrong Thing.
Transforms to the Rescue!
Let’s take a closer look at the formula for eCPM above. We have the sum of impressions in the denominator, that one is easy. The numerator is a sum of products, so let’s first get these products in a transform step:
"transformSpec": {
"transforms": [
{
"type": "expression",
"name": "ads_spend",
"expression": "1.0 * ads_impressions * ecpm"
}
]
}
Then we define a new metric based on this transform like so:
{
"type": "doubleSum",
"name": "sum_ads_spend",
"fieldName": "ads_spend"
}
The rest is straightforward: let’s drop the individual (e)cpm values since we cannot meaningfully sum them up, and make sure we keep ad_network_id as the only dimension. Then the rollup works just fine:
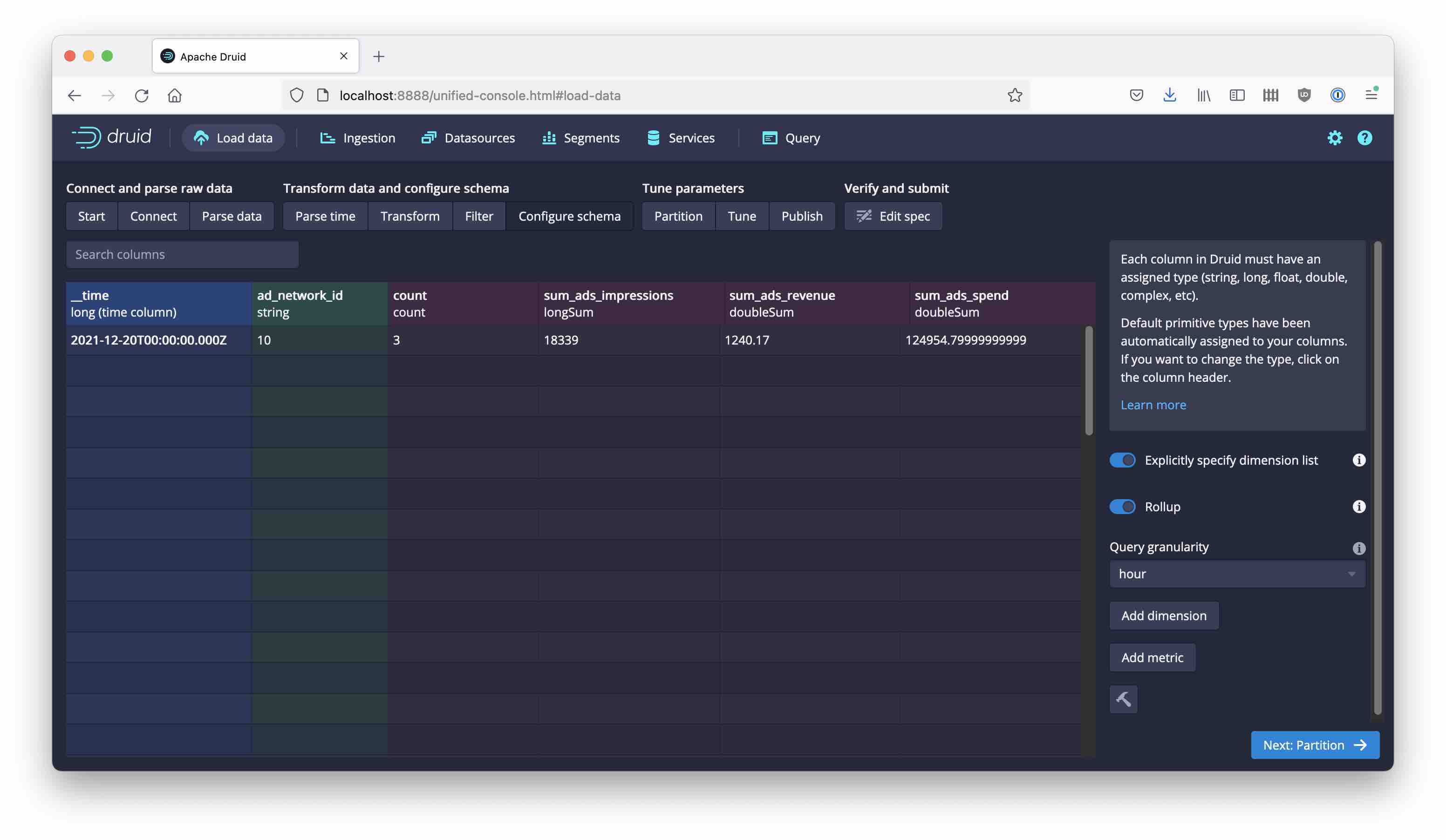
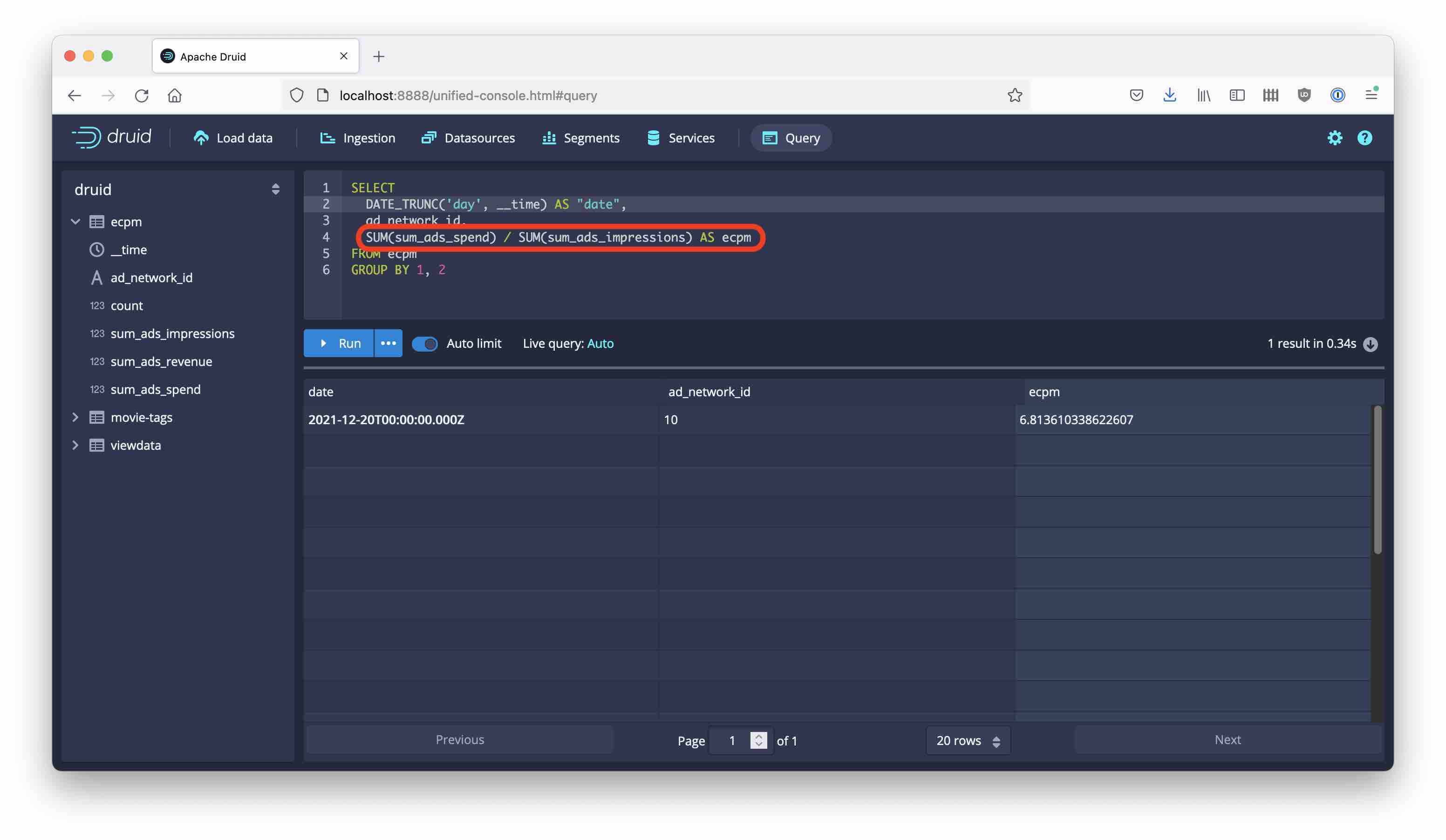
The final step to get to the eCPM metric is then done in the query, as it should be:
SELECT
DATE_TRUNC('day', __time) AS "date",
ad_network_id,
SUM(sum_ads_spend) / SUM(sum_ads_impressions) AS ecpm
FROM ecpm
GROUP BY 1, 2
Note how we are summing over the summed values. This is perfectly legal and does exactly what we want according to the formula above!
For those who want to try it out themselves, here is the complete ingestion spec, with inline data:
{
"type": "index_parallel",
"spec": {
"ioConfig": {
"type": "index_parallel",
"inputSource": {
"type": "inline",
"data": "date|ad_network_id|ads_impressions|ads_revenue|ecpm\n2021-12-20|10|2343|543.15|5.4\n2021-12-20|10|3453|343.12|3.1\n2021-12-20|10|12543|353.9|8.1"
},
"inputFormat": {
"type": "tsv",
"findColumnsFromHeader": true,
"delimiter": "|"
}
},
"tuningConfig": {
"type": "index_parallel",
"partitionsSpec": {
"type": "hashed"
},
"forceGuaranteedRollup": true
},
"dataSchema": {
"dataSource": "ecpm",
"timestampSpec": {
"column": "date",
"format": "auto"
},
"granularitySpec": {
"queryGranularity": "hour",
"rollup": true,
"segmentGranularity": "month"
},
"dimensionsSpec": {
"dimensions": [
"ad_network_id"
]
},
"metricsSpec": [
{
"name": "count",
"type": "count"
},
{
"name": "sum_ads_impressions",
"type": "longSum",
"fieldName": "ads_impressions"
},
{
"name": "sum_ads_revenue",
"type": "doubleSum",
"fieldName": "ads_revenue"
},
{
"type": "doubleSum",
"name": "sum_ads_spend",
"fieldName": "ads_spend"
}
],
"transformSpec": {
"transforms": [
{
"type": "expression",
"name": "ads_spend",
"expression": "1.0 * ads_impressions * ecpm"
}
]
}
}
}
}
Learnings
- Druid is the database of choice for AdTech data; one of the reasons is the extremely efficient data representation as rollup.
- However, valuable metrics such as eCPM seem not to be available easily with rollup
- Transforms during ingestion present an elegant way to get to the desired result.